

Serverless 推理引擎
私有化部署的 Serverless 模型推理引擎,支持 Gitee AI 众多开源模型的推理和应用,为企业免去自建模型推理系统耗时复杂的工作。相较于传统独占式的推理引擎可显著降低算力成本。

ADVANTAGE
产品优势
部署简单 开箱即用
快速私有化部署,开箱即用。使用标准开放接口,支持轻松接入常见的 AI 科学研究与应用软件生态
降低算力使用成本
可显著降低推理的算力使用成本,比传统独占式的推理引擎降低近 90%
数字基于英伟达T4×8环境下的多模型实验得出
覆盖主流模型
支持主流的 Diffusion、多语言、多模态等多种类模型,可支援文生图、问答、总结、翻译、Embedding 提取等各类应用场景
支持多种算力硬件
从英伟达到国产的燧原、天数智芯、中科曙光等,多种算力都可接入
FEATURES
产品特性
多种访问接口
Serverless 推理引擎主要提供两个层次的多种模型推理访问接口。
Web API
Native Python Library
通过符合常见标准的 Web API,便捷接入现有 AI-Native 软件生态
curl https://api-inference.ai.gitee.com/models/gpt2 \
-X POST \
-d '"你好?Gitee AI 的 serverless 服务应该怎么使用?"' \
-H "Authorization: Bearer ${API_TOKEN}"
稳定的推理性能
在 Serverless 推理引擎中,一份 API Token 与一个独立的保障性能的推理通道相对应。
- 不同的推理通道在性能、数据、安全方面保障隔离性。
- 使用相同 API Token 发送的请求将在推理通道中排队,等候推理。

高效的服务端缓存
Serverless 推理引擎包含一系列缓存系统,与算法深度结合,充分利用分级异构内存空间,减少推理过程中的重复计算。

支持丰富的 LoRA 扩展
Serverless 推理引擎支持在运行时按需配置 LoRA,快速实现大模型的个性化定制,随插随用,轻巧方便。
TECH HIGHLIGHTS
技术亮点
整体框架

解聚合(Disaggregation)
为了在共享算力基础设施上高效支持千模在线推理,Serverless 推理引擎采用了数据和计算解聚合的架构方案,使算力设备可以用不同的模型为前后相邻的请求提供服务

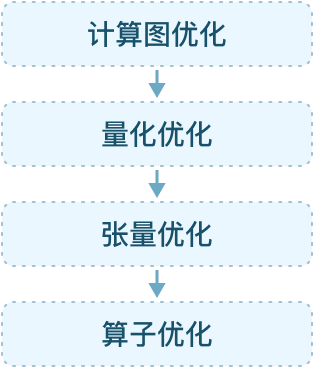
编译优化
支持多种框架的多种算法模型,优化模型运行性能

多种后端算力支持
从英伟达、英特尔到国产的燧原、天数智芯、中科曙光等,多种算力都可接入。同时支持跨不同类型的算力调度。
