快速开发古诗词生成器
应用简介
- 使用应用,借助 AI 模型能力,您可以构建一个创意十足、功能强大的 Web 程序。
- Gitee AI 的应用可以自由编写任何程序,您可以选择预设的 Streamlit 和 Gradio 常用的 SDK。您也可以使用 Dockerfile 来高度自定义运行环境。
- 您可以通过 transformers 、diffusers 库加载 Gitee AI 模型,也可以使用 HTML、JS 等任意编程语言构建界面、调用 Gitee AI 模型引擎 或其他渠道提供的 API 服务。
- 在线部署后,可通过浏览器直接访问、分享您的应用、推广您自己的模型、创意,而无需考虑服务器、算力资源、域名、部署等复杂繁琐问题。
Hello Gitee AI!
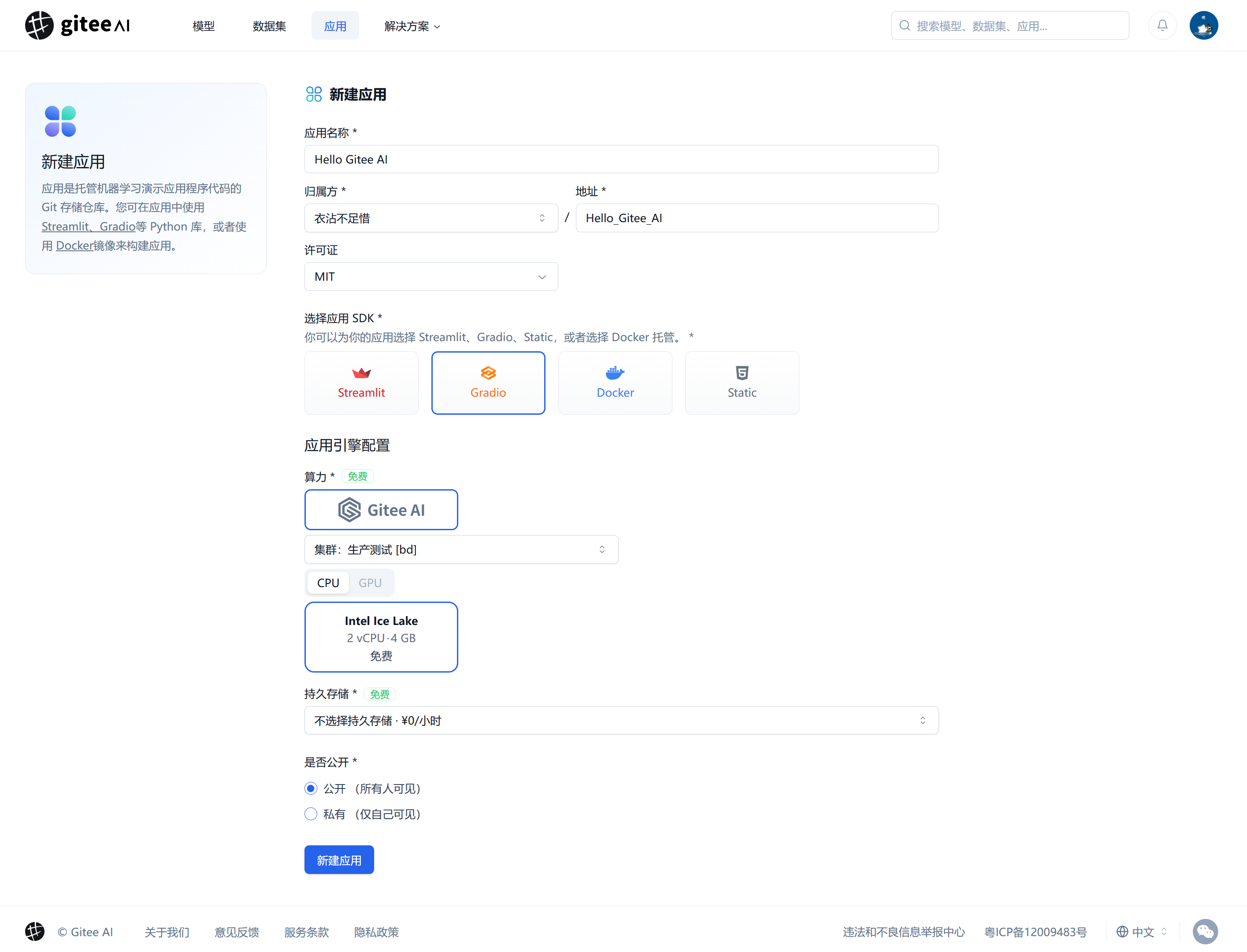
1. 新建应用
前往新建应用界面,填写应用名称、地址、这里选择应用 SDK 为 Gradio, 这里选择免费 2 核 4G 算力,最后点击“新建应用”。
SDK 说明:
- Gradio:您的应用将预设一个 Gradio,它是一个 Python 库,常用于快速构建 AI 应用的用户界面。 您的程序需要 app.py 作为入口,并运行在 7860 端口。
- Streamlit:您的应用将预设一个 Streamlit,它是一个 Python 库,常用于快速构建数据应用的用户界面。您的程序需要 app.py 作为入口,并运行在 7860 端口。
- Docker:您可以使用 Dockerfile 来高度自定义您的应用。您的程序需要运行在 7860 端口。
- Static:纯前端的浏览器程序,您可以上传静态文件,如 HTML、JS、CSS 等,以 index.html 作为程序入口,常用于使用 JS 调用 API 服务,构建 AI 应用。
2. 应用初始界面
新建应用后,您将看到应用的初始界面,您可以在这里查看您的应用信息、代码、git 仓库信息、日志、设置等。
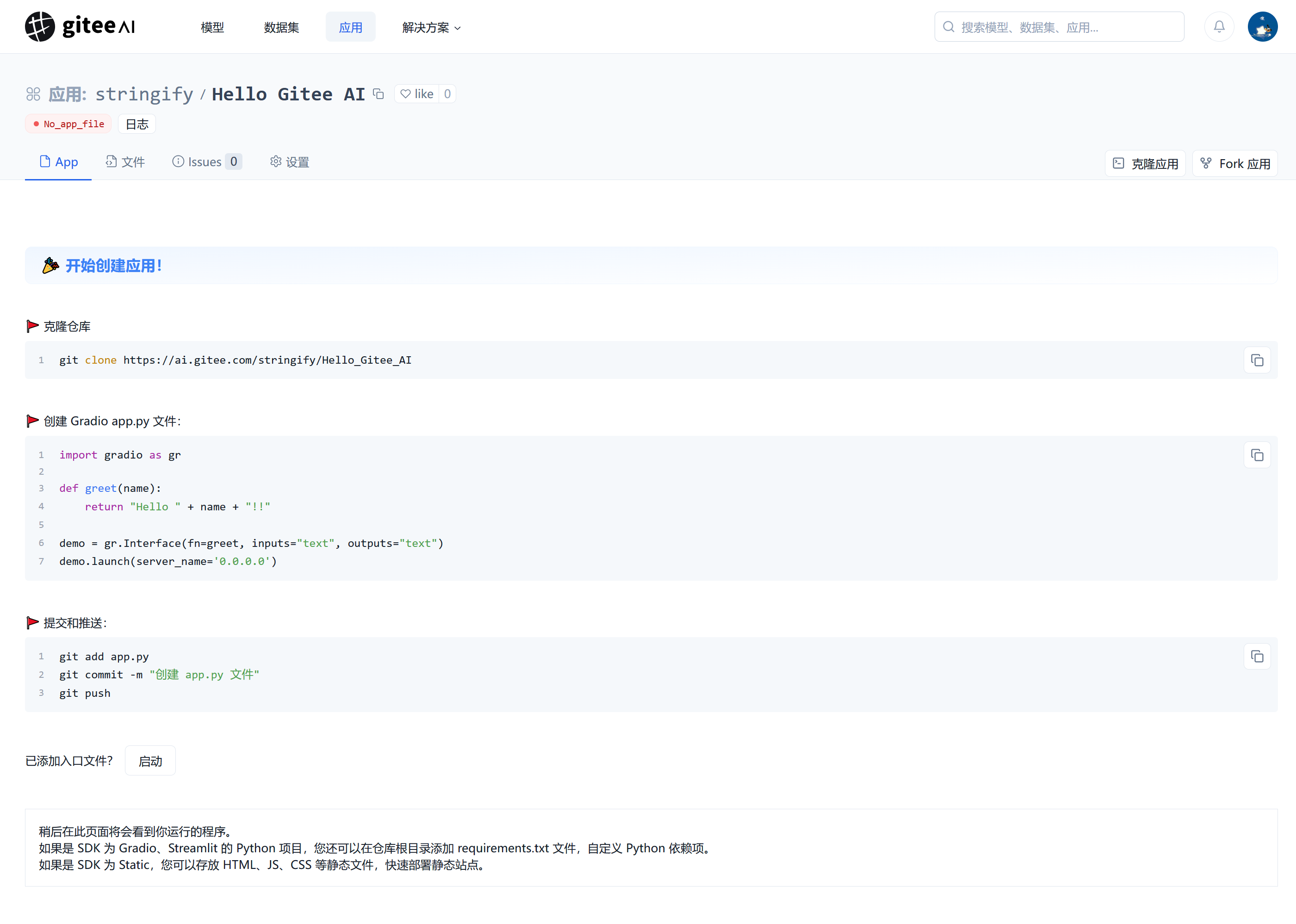
- 您可以选择 git 克隆代码仓库到本地,编写代码后推送到 Gitee AI 仓库,或者直接在"文件" 中在线编辑代码。本次教程使用 git 克隆。
执行 git clone git@https://ai.gitee.com:stringify/Hello_Gitee_AI 将仓库克隆到您的设备。
使用 SSH 克隆,如未配置 Gitee SSH 公钥,请 前往添加 Gitee SSH 公钥
3. 创建入口文件、提交文件到 Gitee AI
在代码仓库根目录下创建 app.py 文件,写入以下代码:
import gradio as gr
def greet(name):
return "Hello " + name + "!!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch(server_name='0.0.0.0', server_port=7860)
提交并推送代码到 Gitee AI 仓库
git add app.py
git commit -m "创建 app.py 文件"
git push
4. 应用代码更新提示
应用代码已推送到 Gitee AI,刷新界面,顶部会看到提示重启应用
重启应用后,您的应用将重新构建、部署,您可以在日志中查看相关信息。 修改代码或出现系统异常后,您也可以进入设置-功能界面,点击出厂重启,更新应用。
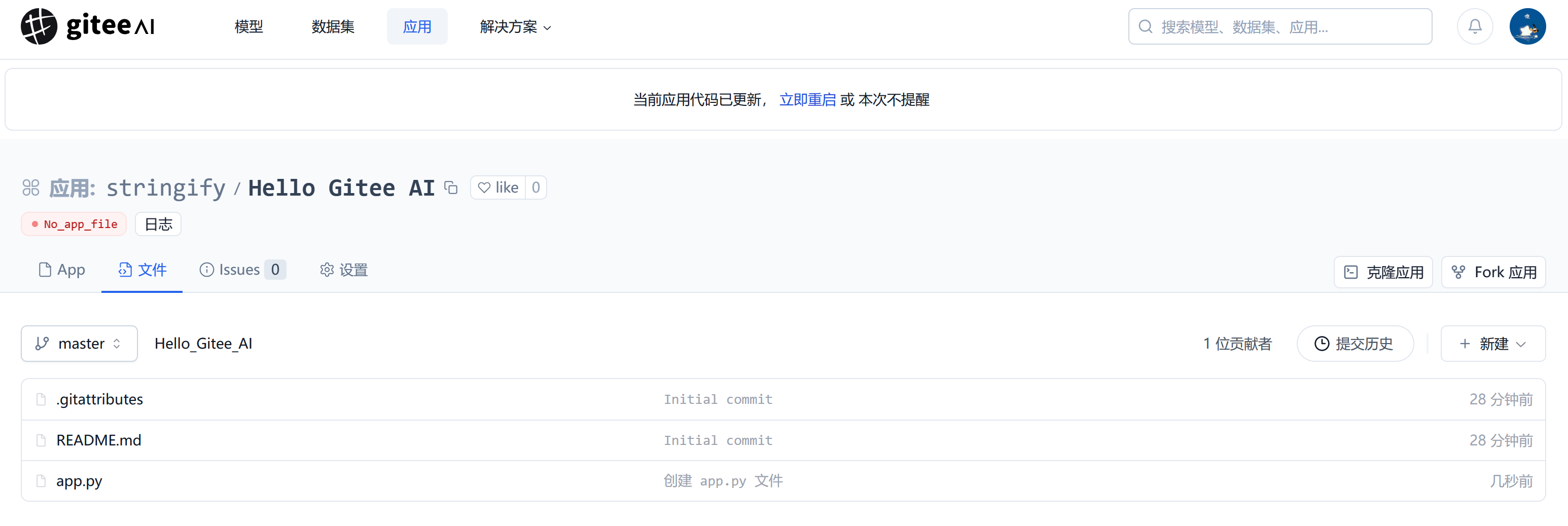
5. 点击立即重启
稍等片刻,您的应用将部署,您可以在日志中查看部署进度。
代码更新后,重启应用将进入
Building状态,稍等片刻刷新页面可看应用状态显示Running on CPU,即启动成功。
-
应用状态说明:
状态名称 描述 No_app_file 应用没有入口文件 Building 应用正在拉取代码、构建中 Readying 应用正在准备中,可能是正在执行仓库代码、下载模型 Running on CPU 应用运行在 CPU 算力上 Running on Nvidia A10 应用运行在 Nvidia A10 显卡算力上 Pending 应用正在等待中,可能是正在分配资源中、资源不足 Paused 用户手动暂停应用 Stopped 应用异常停止,可能是系统或代码出现异常 Runtime_error 应用运行时出现错误,可能是代码或系统错误 SLEEPING 应用休眠中,满足休眠倒计时
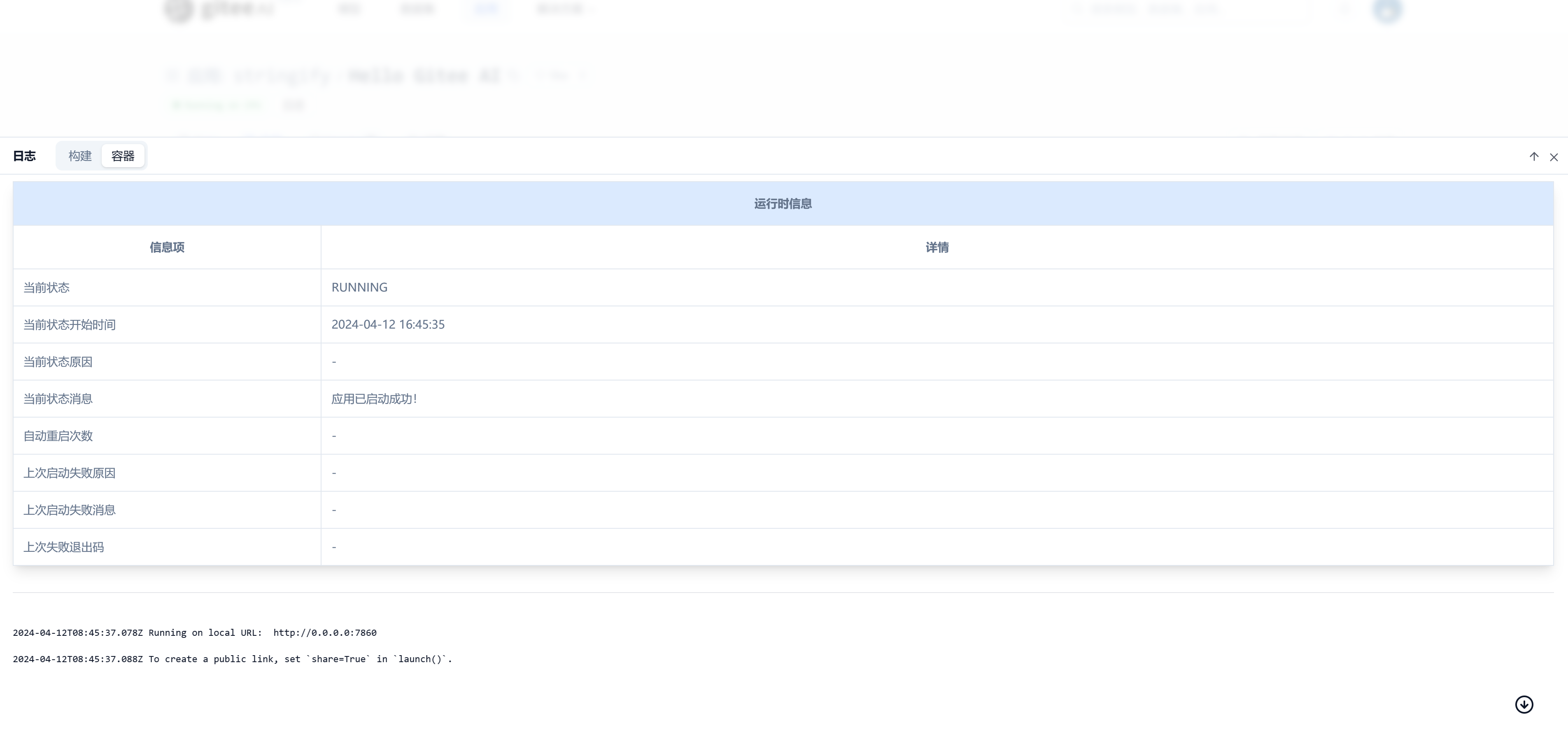
6. 应用部署成功!查看应用界面:

中文古诗生成器
前面只是小试牛刀,现在尝试真正的 AI 能力:
1. 修改 app.py 代码
现在,您可以尝试使用 Gitee AI 模型库中的模型,如中文古诗生成器,将下面代码替换到 app.py 中:
import torch # 导入 PyTorch 库,�用于深度学习任务。
import gradio as gr # 导入Gradio库,用于构建交互式界面。
import torch.nn.functional as F
from transformers import BertTokenizer, GPT2LMHeadModel # 从transformers库中导入BertTokenizer和GPT2LMHeadModel,用于自然语言处理和文本生成任务。
# Gitee AI 支持 transformers diffusers 等库,您可以直接使用 Gitee AI 模型库中的模型,前往 https://ai.gitee.com/models 查看更多模型。您也可以使用其他方式下载模型(例如 git 克隆、其他源下载)
tokenizer = BertTokenizer.from_pretrained("hf-models/gpt2-chinese-poem") # 用预训练的 BertTokenizer 加载中文诗歌生成模型的tokenizer。
model = GPT2LMHeadModel.from_pretrained("hf-models/gpt2-chinese-poem") # 使用预训练的GPT-2模型加载中文诗歌生成模型。
model.eval() # 将模型设置为评估模式,保证推理阶段的一致性、稳定性和效率。评估模式与训练模式相对应。
# 定义了一个函数,用于对模型输出的logits进行top-k和top-p过滤:
# 确保在生成文本时,只有概率最高的几个token被考虑,提高生成文本的质量和连贯性。
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
assert logits.dim() == 1
top_k = min(top_k, logits.size(-1))
if top_k > 0:
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
sorted_indices_to_remove = cumulative_probs > top_p
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
return logits
# 定义了生成函数,接受一个输入文本,然后利用 AI 模型生成新文本。
def generate(input_text):
input_ids = [tokenizer.cls_token_id]
input_ids.extend( tokenizer.encode(input_text, add_special_tokens=False) )
input_ids = torch.tensor( [input_ids] )
generated = []
for _ in range(100):
output = model(input_ids)
next_token_logits = output.logits[0, -1, :]
next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf')
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=8, top_p=1)
next_token = torch.multinomial( F.softmax(filtered_logits, dim=-1), num_samples=1 )
if next_token == tokenizer.sep_token_id:
break
generated.append( next_token.item() )
input_ids = torch.cat((input_ids, next_token.unsqueeze(0)), dim=1)
return input_text + "".join( tokenizer.convert_ids_to_tokens(generated) )
examples = [["不堪翘首暮云中"], ["开源中国"], ["行到水穷处"], ["王师北定中原日"] ,["雪"], ["海上升明月"], ["十年磨一剑"]]
# 创建一个 Gradio 接口,用于接收用户输入,调用 generate 函数生成文本,并返回生成的文本。Gradio 默认启动到 7860 端口。
if __name__ == "__main__":
gr.Interface(fn=generate, inputs="text", outputs="text",examples=examples).queue().launch()
2. 添加 requirements.txt 文件
app.py 代码除了使用到您选择的预设 SDK 中的 Gradio, 还使用到其他库��。 在代码仓库根目录下创建 requirements.txt 文件,写入以下代码提交到仓库:
--extra-index-url https://mirrors.cloud.tencent.com/pypi/simple
torch
transformers
您也可以自定义依赖库版本。Gitee AI 加速依赖下载默认使用了镜像源,您也可自定义替换为其他源:
--extra-index-url https://mirrors.cloud.tencent.com/pypi/simple
gradio==4.26.0
torch
transformers
3. 更新代码后点击页面顶部的"立即重启"按钮或进入设置-功能界面点击"出厂重启",即可查看应用效果。
输入 十年磨一剑 AI 输出 十年磨一剑,未试请长缨。马上高歌起,风尘事不平。
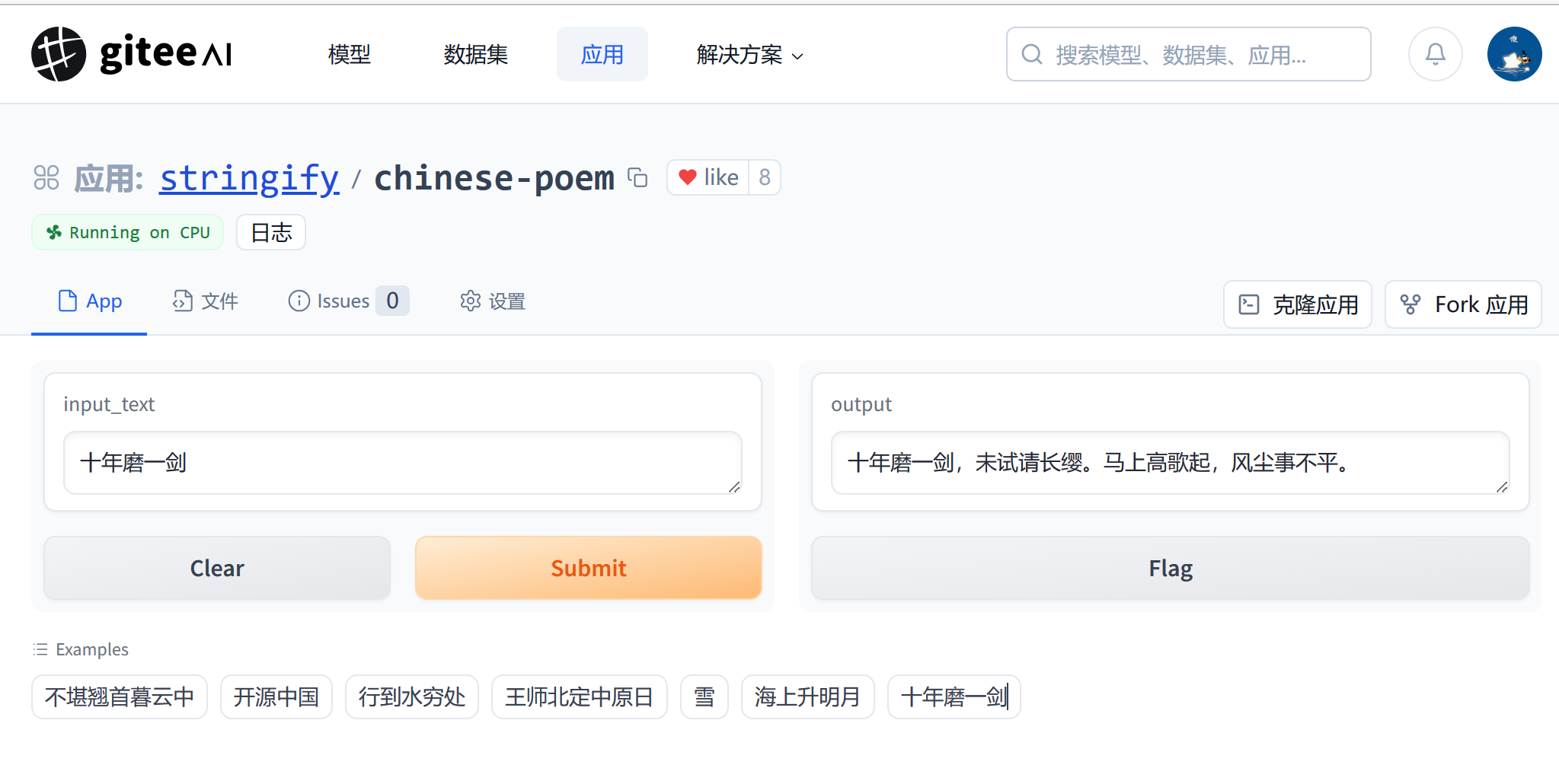
在此示例中,您已经成功构建了一个中文古诗生成器应用!您还可以进入应用设置中升级硬件配置、调整应用信息、添加环境变量、秘钥等。
更多应用示例
- 应用首页
- 文生文: 中文古诗生成器,Gradio + CPU
- 文生图: SD3 中文提示词 ,Gradio + GPU + API
- 文生图: Animagine-xl,Gradio + GPU
- 对话: Llama3-70b-chinese-chat, Gitee AI Serverless API
- 语音合成: ChatTTS,Gradio + GPU
- 文生图: SDXL-Turbo,Gradio + GPU
- 物体检测: 静态页面 Static
- 对话:glm4-chat,Gradio + GPU
- 图生文: Gradio + CPU
- 在线工具:jupyter-lab,Dockerfile
- livebook: Dockerfile