流水线的应用场景
语音模型应用场景
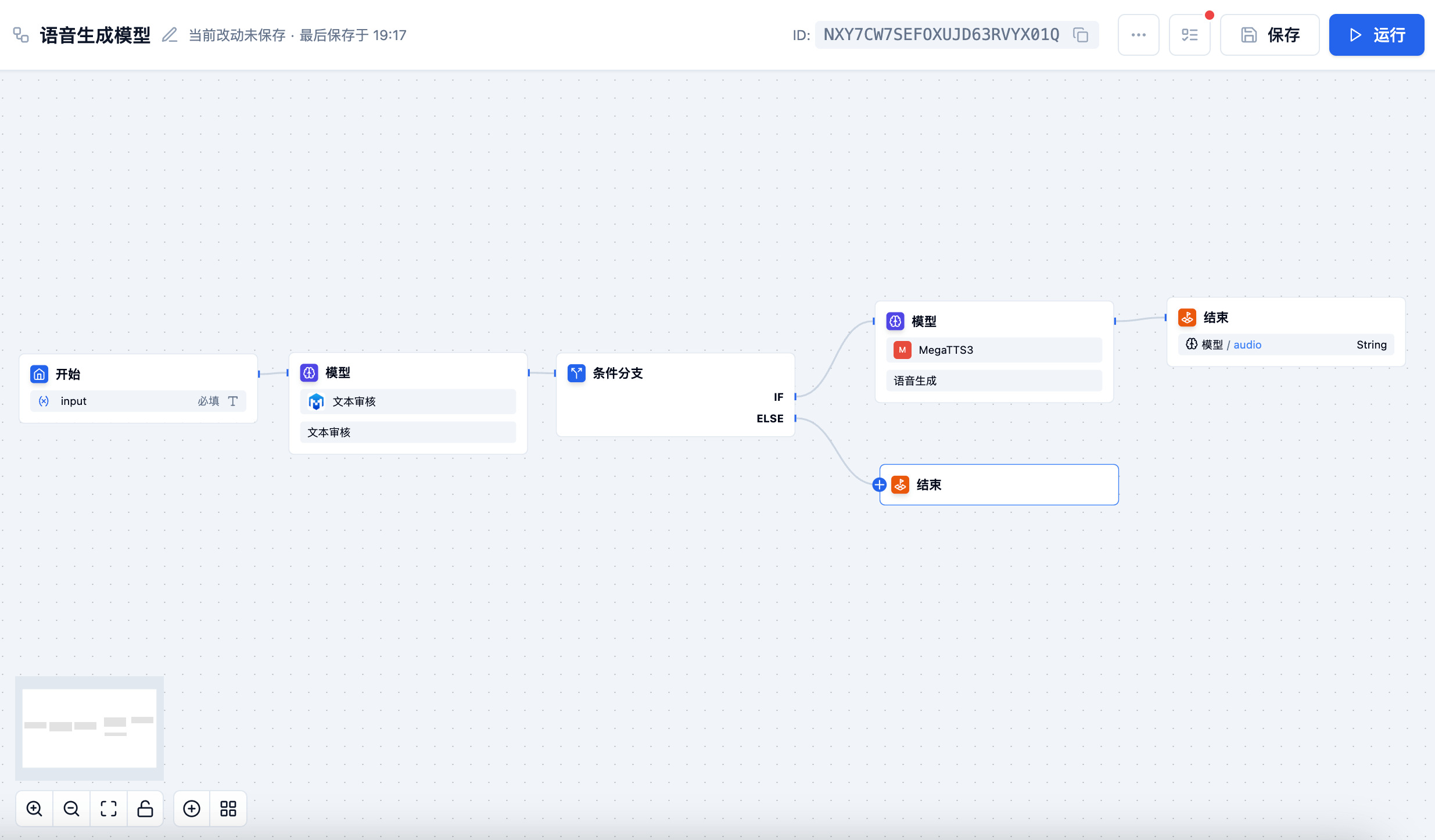
语音模型包括自动语音识别(ASR)和语音合成(TTS)两大类型,为音频内容的理解和生成提供强大能力。
自动语音识别模型
自动语音识别模型能够将语音转换为文字,支持多种语言和方言,广泛应用于各种需要语音理解的场景。

主要应用场景
会议实时转录
在远程协作情景中,实时转写跨语言线上会议内容,生成带时间戳的对话记录,支持关键词检索与重点标记。
典型用例:
- 远程会议自动记录
- 多语言会议同步翻译
- 会议纪要自动生成
视频内容配字幕
在媒体生产情景中,为短视频/长片纪录片自动生成多语言字幕,同步输出字幕文件(SRT/VTT)。
典型用例:
- 视频自动字幕生成
- 多语言字幕制作
- 媒体内容本地化
语音合成模型
语音合成模型能够将文字转换为自然流畅的语音,支持多种音色和情感表达。
主要应用场景
多角色有声内容创作
生成不同性别/年龄的旁白角色音,批量输出带情感变化的配音片段。
典型用例:
- 有声小说制作
- 广告配音生成
- 播客节目制作
- 角色扮演音频
长文本语音播报
将小说章节转换为自然流畅的朗读音频,自动插入呼吸停顿/强调重音。
典型用例:
- 长篇小说朗读
- 新闻播报生成
- 学习材料朗读
图像生成模型应用场景
图像生成模型能够根据文字描述或其他图像生成高质量的图像内容,支持多种创作和编辑场景,为视觉内容创作提供强大支持。
主要应用场景
产品视觉设计
根据商品描述生成高质量产品海报、场景图或营销素材,支持背景替换/风格迁移,确保视觉风格符合品牌调性。
典型用例:
- 电商产品海报自动生成
- 产品场景图批量制作
- 营销素材个性化定制
- 品牌视觉风格统一
- 产品包装设计辅助
创意内容生成
基于文字指令(如"赛博朋克风格的城市夜景")批量生成原创插图、封面图或概念艺术,提升内容吸引力。
典型用例:
- 文章配图自动生成
- 社交媒体内容创作
- 书籍封面设计
- 概念艺术创作
- 广告创意素材制作
图像修复与增强
对老照片等模糊、破损或低分辨率图像进行超分重建、划痕修复、色彩还原,提升历史资料可用性。
典型用例:
- 老照片修复翻新
- 图像去噪处理
- 色彩增强与校正
- 历史文档图像修复
定制化风格迁移
在游戏/影视美术情景中,将概念图自动转换为指定艺术风格(如水墨风、像素风、3D渲染),或统一多张素材的画风一致性。
典型用例:
- 游戏美术资源统一风格
- 影视概念图风格化
- 艺术作品风格转换
- 品牌视觉一致性保证
- 创意风格探索
个性化定制
根据用户喜好和需求,生成个性化的头像、壁纸、装饰图案等专属内容。
典型用例:
- 个人头像定制生成
- 手机壁纸个性化
- 家居装饰图案设计
- 个人品牌视觉创建
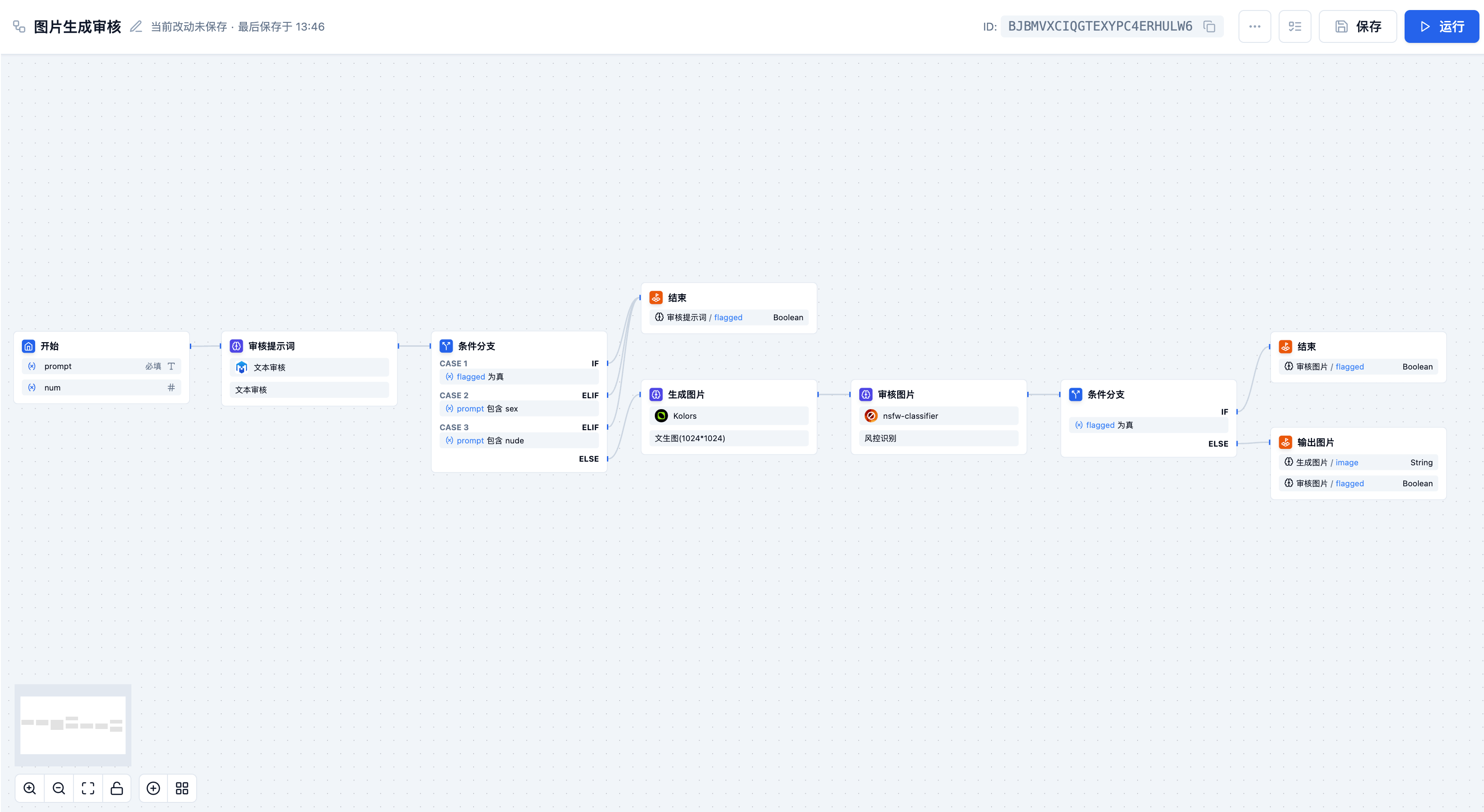
风控识别模型应用场景
风控识别模型专门用于内容安全审核,能够自动识别和过滤不当内容,保障平台和业务的安全合规运营。
主要应用场景
文本内容审核
实时检测用户发布的文本/图片(如评论区、动态),拦截色情、暴力、辱骂信息等违规内容。
检测类型:
- 色情低俗内容识别
- 暴力血腥内容检测
- 恶意攻击言论过滤
- 垃圾广告信息拦截
- 敏感政治内容识别
文件上传风控
扫描用户上传的文档/图片中的敏感内容,防止涉政标识、违禁图片等危险内容传播。
典型用例:
- 文档内容安全扫描
- 图片违规内容检测
- 色情违规图片识别
- 涉政违规图片识别
文本生成模型应用场景
文本生成模型(LLM) 节点是能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在 API 流水线的不同环节使用。包含多种主流模型,如 DeepSeek、Qwen 系列等。
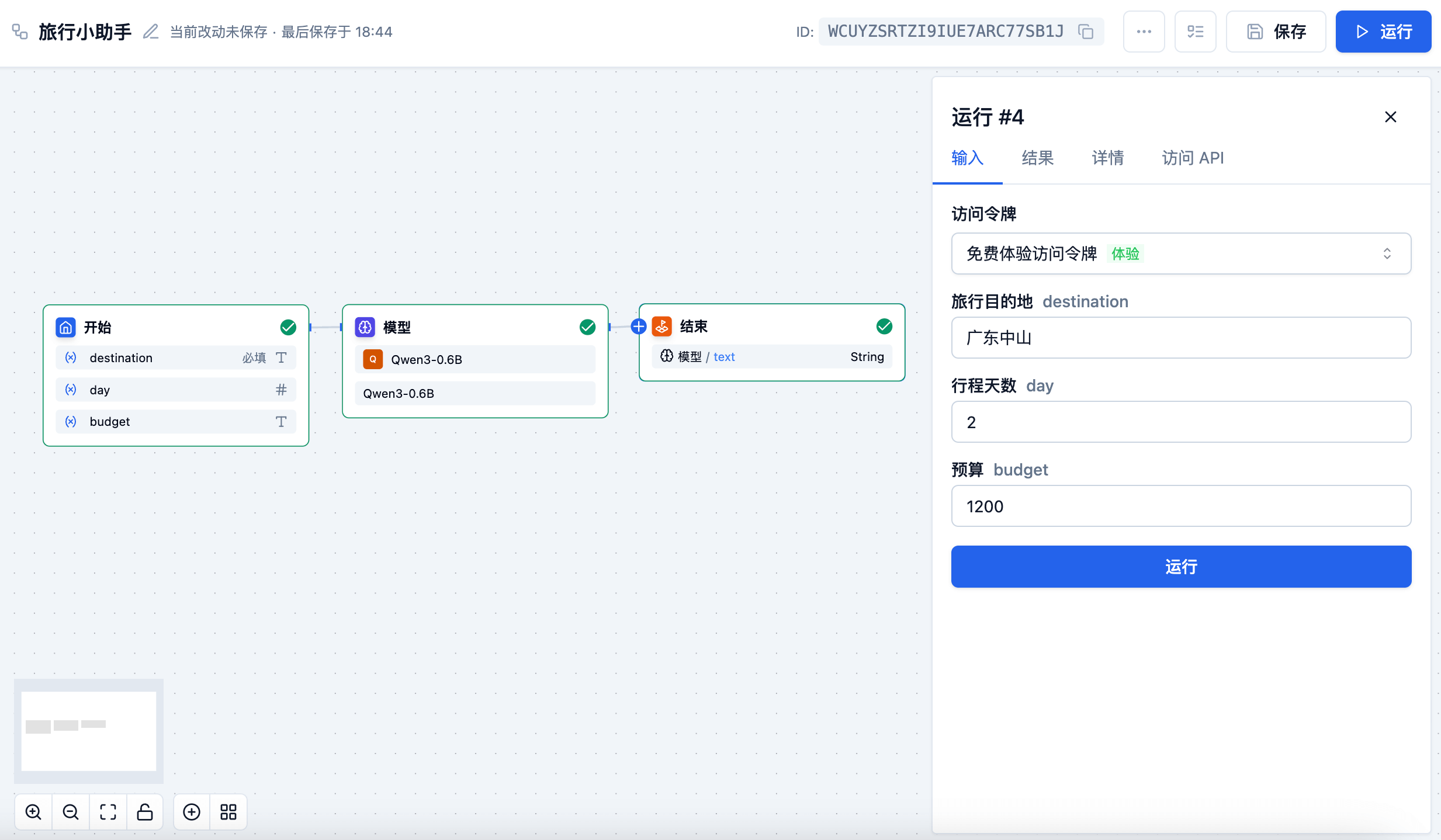
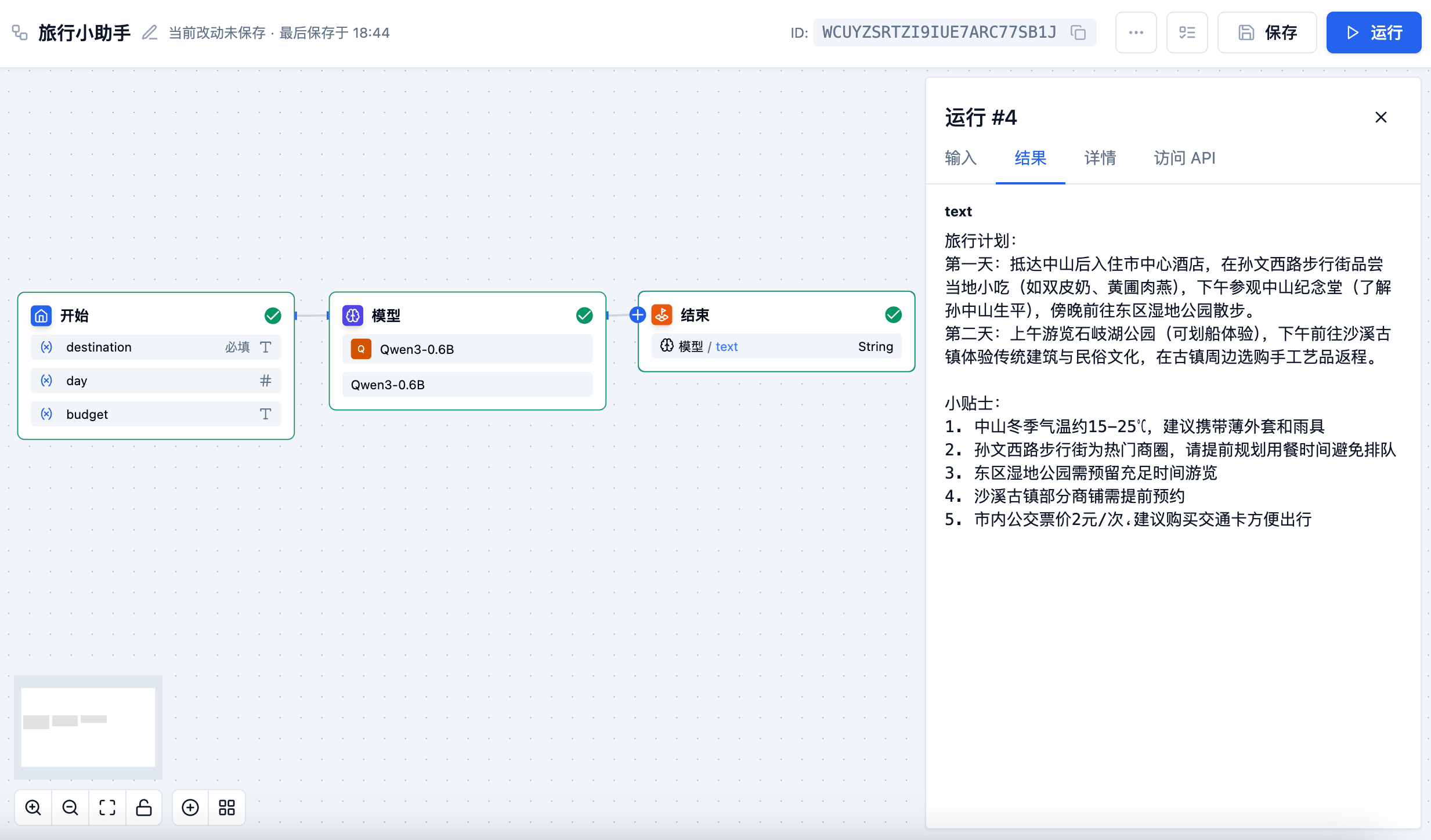
主要应用场景
意图识别
在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
典型用例:
- 客服机器人自动分类用户问题(技术支持、退款申请、产品咨询)
- 智能路由用户请求到相应的专业客服团队
- 实时分析用户情绪,调整对话策略
文本生�成
在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
典型用例:
- 营销文案自动生成
- 产品说明书批量创建
- 个性化邮件内容生成
- 社交媒体内容创作
内容分类
在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
典型用例:
- 自动邮件分拣系统
- 内容审核分类
- 文档自动归档
- 用户反馈分类分析
文本转换
在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
典型用例:
- 多语言内容本地化
- 实时聊天翻译
- 文档翻译批处理
- 跨语言信息检索
代码生成
在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
典型用例:
- 自动化测试用例生成
- API文档生成
- 代�码重构建议s
- 编程教学辅助
配置要点
- 模型选择:根据任务复杂度选择合适的模型规模
- 提示词优化:针对具体场景设计专业的提示词模板
- 参数调整:根据输出要求调整 temperature、max_tokens 等参数
- 变量设置:合理设置输入输出变量,便于上下游节点数据传递
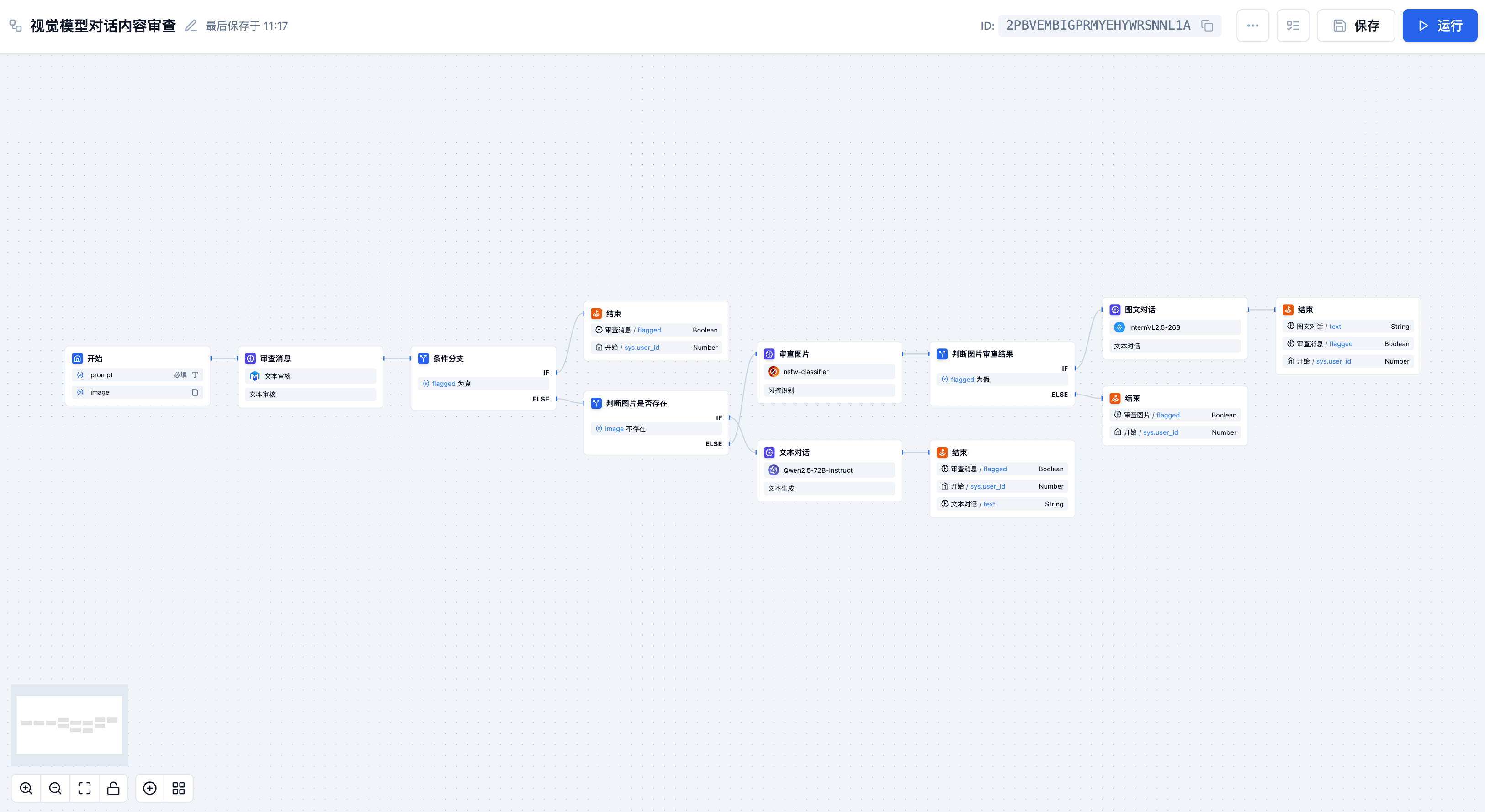
视觉模型应用场景
视觉模型能够理解和分析图像内容,提供智能的图像识别、理解和分析能力,广泛应用于各种需要视觉理解的场景。
主要应用场景
图像内容理解与问答
在智能客服情景中,分析用户上传的产品故障图片、操作界面截图或实物照片,精准识别内容并回答相关问题。
典型用例:
- 产品故障图片自动诊断
- 操作界面问题识别
- 产品外观质量检测
- 用户问题可视化分析
图文信息提取与处理
在文档自动化处理中,解析扫描文档、票据、合同或带文字信息的图片,提取关键字段、识别表格数据或进行文字翻译。
典型用例:
- 发票信息自动提取
- 合同关键条款识别
- 表格数据结构化
- 多语言文档翻译
- 身份证信息识别
工业视觉检测
在生产线自动化质检中,实时分析产品/零部件的高清图像,检测划痕、裂纹、装配错误、尺寸偏差、异物或印刷缺陷。
典型用例:
- 产品表面缺陷检测
- 装配完整性验证
- 尺寸规格自动测量
- 印刷质量控制
- 异物检测与分拣
教育/培训辅助
在智能教育平台中,识别教材插图、实验图片、手写解题步骤或学生绘画作品,提供解释、批改、��答疑或生成相关的学习问题。
典型用例:
- 手写作业自动批改
- 实验结果图像分析
- 教材内容理解辅助