PDF 文档解析
PDF-Extract-Kit
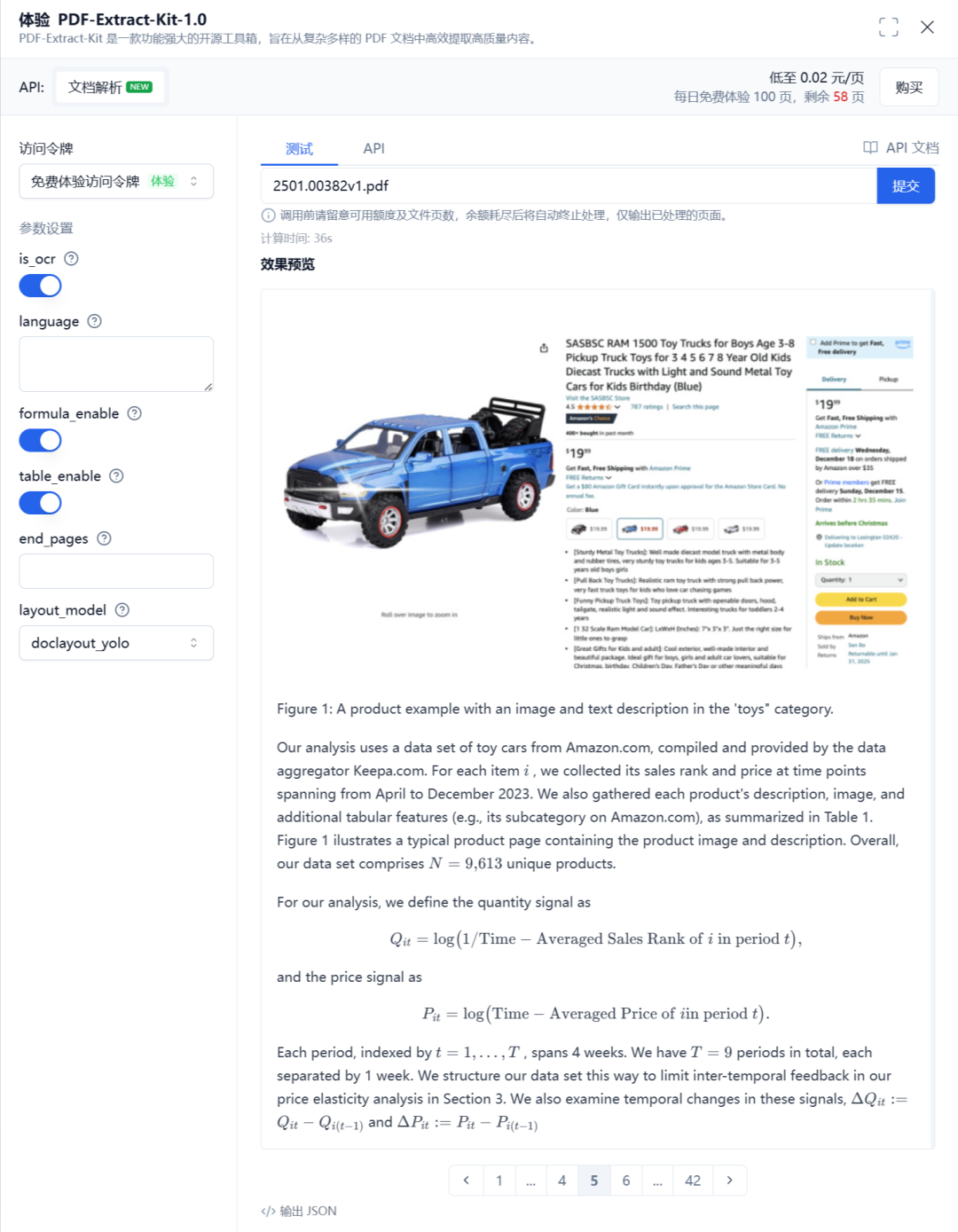
PDF-Extract-Kit 专为从各类复杂 PDF 文档中高效提取高质量内容而设计。它具备以下特点:
- 能够精确还原原始文档的布局。
- 输出内容为 Markdown 格式,便于阅读。
- 输出内容按照分页、语义进行分段。
- 可识别数学公式。
- 可识别表格。
- 可识别多语言。
适用场景:
- 知识库、数据集:直接用于 AI 的 RAG、微调和机器学习等场景。
- 企业文档数字化:提取传统纸质文件图像或扫描版文档信息,提高企业管理数字化能力。
- 多语言文档处理:接口支持多种语言的文字识别,可以自动区分文档中的语言。
- 在科研领域,数学、物理、工程等学科中,适用于识别文档中数学公式和复杂表格。
- 在线文档服务与 SaaS 应用,提供一站式文档解析、格式转换和内容抽取服务。
使用方法
您可以点击 PDF-Extract-Kit 在线免费体验。以下是代码调用示例。
- Bash
curl https://ai.gitee.com/v1/async/documents/parse \
-X POST \
-H "Authorization: Bearer 你的私人令牌" \
-F "model=PDF-Extract-Kit-1.0" \
-F "is_ocr=true" \
-F "formula_enable=true" \
-F "table_enable=true" \
-F "layout_model=doclayout_yolo" \
-F "file=@path/to/file.pdf"
参数说明:
- 私人令牌:用于验证调用身份,点击 私人令牌 获取。
- model:填写 PDF-Extract-Kit 使用指定的大模型。
- file:需要解析的文件。
- 支持
pdf,png,jpg,gif,docx,pptx格式的文件。 - 文件不超过
100MB。
- 支持
- is_ocr:是否启用 ocr。false 不启用时将不会识别图片中的文字。
- include_image_base64:启用后,响应的 markdown 中将内嵌 base64 图片,否则图片将上传到云存储,并提供临时链接,仅 7 日有效。
- formula_enable 是否启用公式解析。
- table_enable 是否启用表格解析。
- language 指定文字语言用于提高识别精确度,默认不填写为自动识别。可选语言:ch、en、korean、japan、chinese_cht、ta、te、ka、latin、arabic、cyrillic、devanagari。
- end_pages 要处理的页数,即处理前 N 页。
- layout_model:布局分析模型。解析时,将会分析文档布局,不同模型影响生成的质量。可选:
doclayout_yolo(默认值,更快、更准确)layoutlmv3(更稳定)
使用示例
该接口为异步接口,需要先提交任务,获取到任务 ID,随后再根据 ID 轮询获取执行结果。CURL 提交任务后将会响应:
{
"task_id": "AAC2KETEYJVKER04U6RNMHJTOGLVEG1B",
"status": "waiting",
"created_at": 1742885184998,
"urls": {
"get": "https://ai.gitee.com/api/v1/task/AAC2KETEYJVKER04U6RNMHJTOGLVEG1B",
"cancel": "https://ai.gitee.com/api/v1/task/AAC2KETEYJVKER04U6RNMHJTOGLVEG1B/cancel"
}
}
再根据 task_id 获取最终执行结果:
curl https://ai.gitee.com/v1/task/AAC2KETEYJVKER04U6RNMHJTOGLVEG1B/
--header 'Authorization: Bearer 你的私人令牌'
{
"task_id": "AAC2KETEYJVKER04U6RNMHJTOGLVEG1B",
"output": {
"segments": [
{
"index": 1,
"content": "# 第一段 xxxx"
},
{
"index": 2,
"content": "# 第二段 xxxx"
}
]
},
"status": "success",
"created_at": 1742885185000,
"started_at": 1742885188000,
"completed_at": 1742885190000,
"urls": {
"get": "https://ai.gitee.com/api/v1/task/AAC2KETEYJVKER04U6RNMHJTOGLVEG1B",
"cancel": "https://ai.gitee.com/api/v1/task/AAC2KETEYJVKER04U6RNMHJTOGLVEG1B/cancel"
}
}
当响应中的 status 变为 success,即解析成功。output 为解析结果,segments 为解析结果分段,分段基于分页或语义逻辑进行划分。
接口参考