大语言模型微调
模型类别
我们目前支持Qwen2.5系列的多个纯文本对话类的模型微调,后续会支持更多模型。
数据集准备
数据集类型
对于纯文本类数据集,我们目前支持 OpenAI 的 messages 对话格式的类型,后续将支持更多类型。一轮对话典型的数据集格式如下所示:
{
"messages": [
{
"role": "system",
"content": "系统提示词(选填)"
},
{
"role": "user",
"content": "用户的问题内容"
},
{
"role": "assistant",
"content": "语言模型的回答内容"
}
]
}
- 一轮对话的数据由一条
messages的json数据组成,包含三种角色:system、user、assistant,而content包含该角色的会话内容。 system表示“系统提示词”,一轮对话只能有一条且必须是第一个,它是一个指令权重很高的内容,用于初步规范模型的通用行为。user和assistant分别表示“用户提示词”和“模型回复”。模型在训练中要根据会话记录学习assistant的内容,因此数据集中要至少包含一对 user 和 assistant 的问答对。- 会话不限长度,
user和assistant的会话内容可以不止一条。
数据集保存类型
我们目前仅支持 jsonl的保存格式,文件内容由多行 message 的对话数据组成,内容示例如下:
{"messages": [{"role": "system", "content": "you are a helpful assistant. "}, {"role": "user", "content": "什么是大语言模型?"}, {"role": "assistant", "content": "大语言模型(Large Language Model,简称LLM)是指使用大量文本数据训练的深度学习模型,能够生成自然语言文本或理解语言文本的含义,是自然语言处理领域的重要工具,可以处理多种自然语言任务"}]}
{"messages": [{"role": "system", "content": "you are a helpful assistant. "}, {"role": "user", "content": "请你证明费马大定理"}, {"role": "assistant", "content": "由于费马大定理的证明非常复杂且涉及高级的数学概念,我无法在这里给出一个完整的证明过程。"}]}
{"messages": [{"role": "system", "content": "you are a helpful assistant. "}, {"role": "user", "content": "热胀冷缩是什么导致的?"}, {"role": "assistant", "content": "热胀冷缩现象是物质的一种基本性质,其主要原因与物质内部的微观结构以及粒子间的相互作用有关。"}, {"role": "user", "content": "感谢你的回答!"}, {"role": "assistant", "content": "不用谢,很高兴可以帮到你,还有什么其他问题吗?"}]}
同时,您可以通过此处下载该文件用于参考。
模型微调
微调种类简介
SFT (监督微调)
监督微调(SFT)通过一个包含明确问题和答案的规范数据集继续训练一个已有的模型,使得最终训练好的模型生成的内容尽可能与数据集中相似。应用SFT微调的可能场景有:
- 提升模型在特定领域或场景的能力:原预训练模型的问答效果在特定场景或任务中较差,通过拿这些领域或场景的数据内容训练,模型可以学习这些场景下的回复内容、格式、语气等,以提升相应的能力。
- 有限数据的训练:SFT微调不要求预训练那样巨量的数据,仅需很少且质量很高的数据,就可以以更低成本的让模型实现回复预期内容。
- 知识蒸馏:往往在行业中,仅需使用模型某项很强的能力,但该模型又因为尺寸很大导致使用成本过高。通过使用该模型生成的数据继续训练一个成本更低的且可以达到预期效果的模型部署,可以显著降低在指定项目的使用成本。
进入训练界面
首先在我们的模型广场主页中,点击“工作台”进入到个人主页,如下图所示:

进入到个人主页后,点击左边栏中的“模型微调”即可进入到个人微调总览界面。如下图所示:
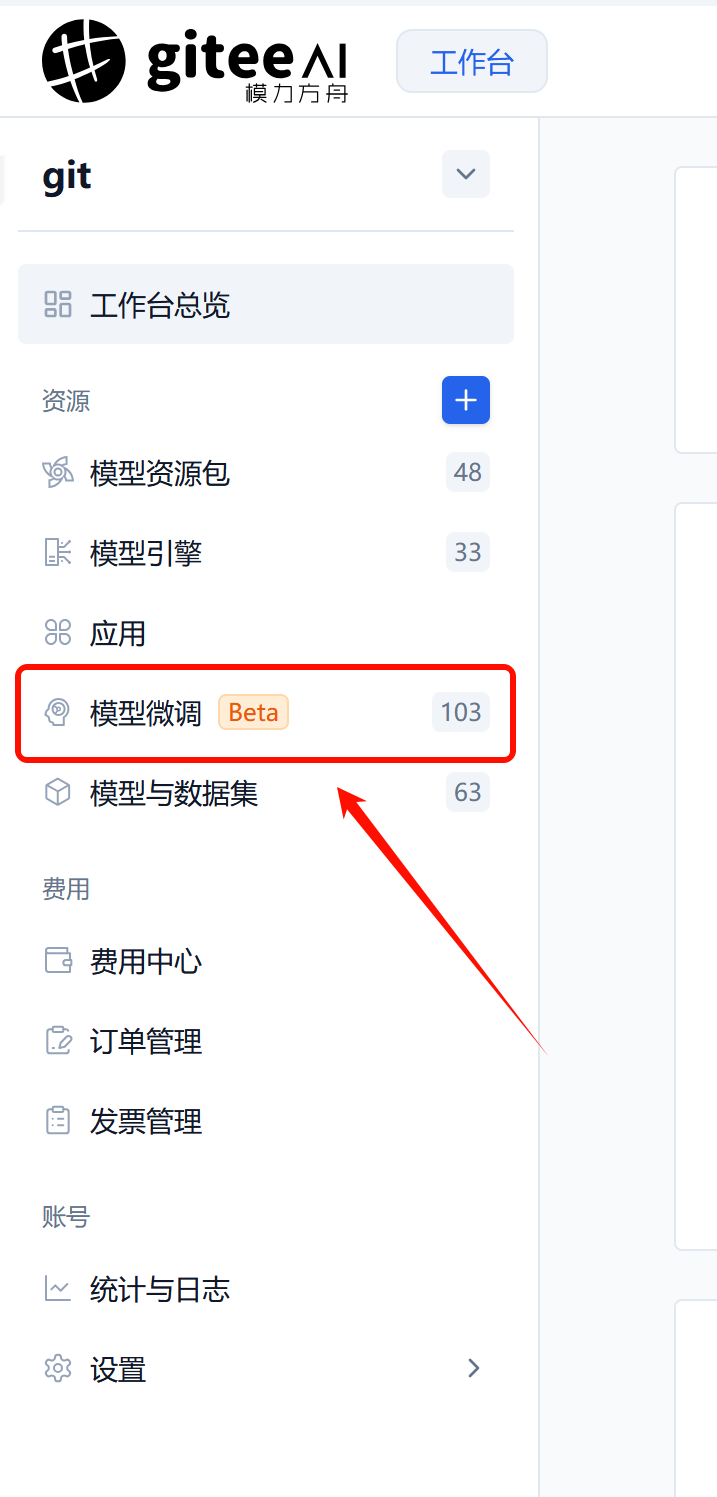
在个人微调总览的右上角,点击“新建任务”,即可新建一个微调任务。如下图所示:

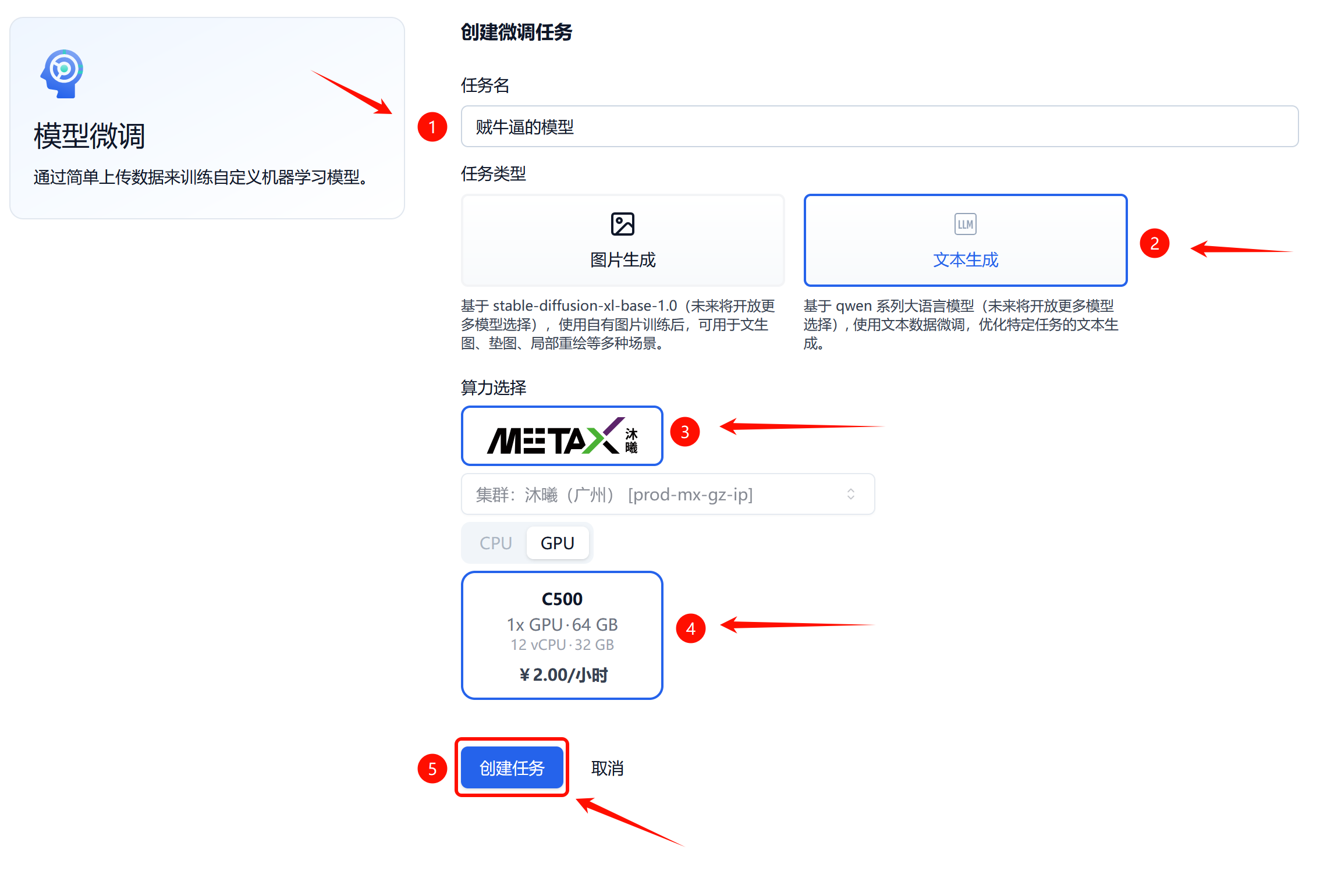
微调任务选项的界面如下图所示。首先为新任务取一个响亮的名字,然后选择“文本生成”,接下来做“算力选择”,最后点击“创建任务”后,就可以愉快的开始训练之旅了~
配置训练参数
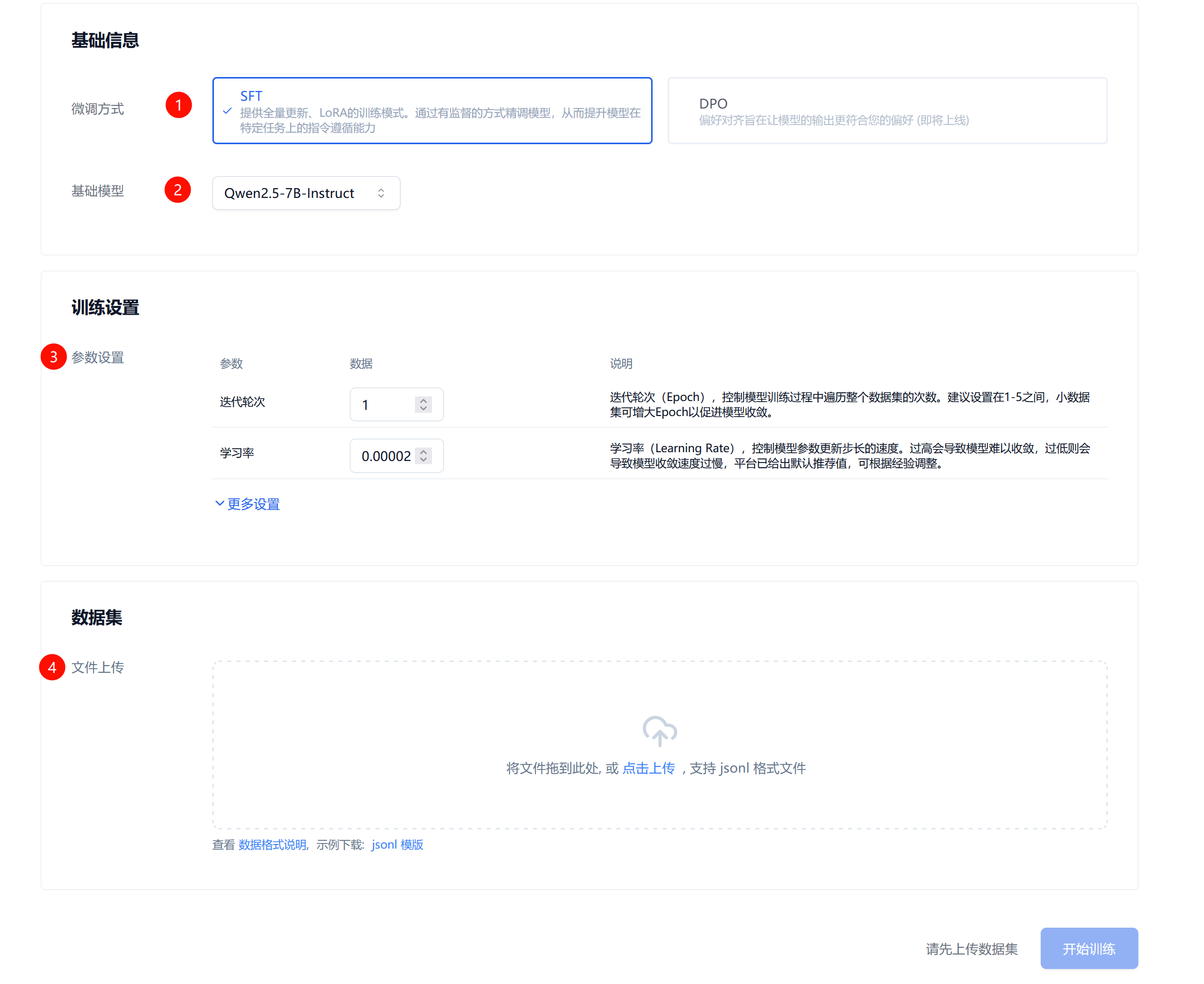
在训练任务开始前,您需要配置一些参数,界面如下图所示。首先选择要使用的“微调方式”和“基础模型”。然后训练设置中可以根据说明理解调节训练参数,点击“更多设置”可以配置更高级的参数。
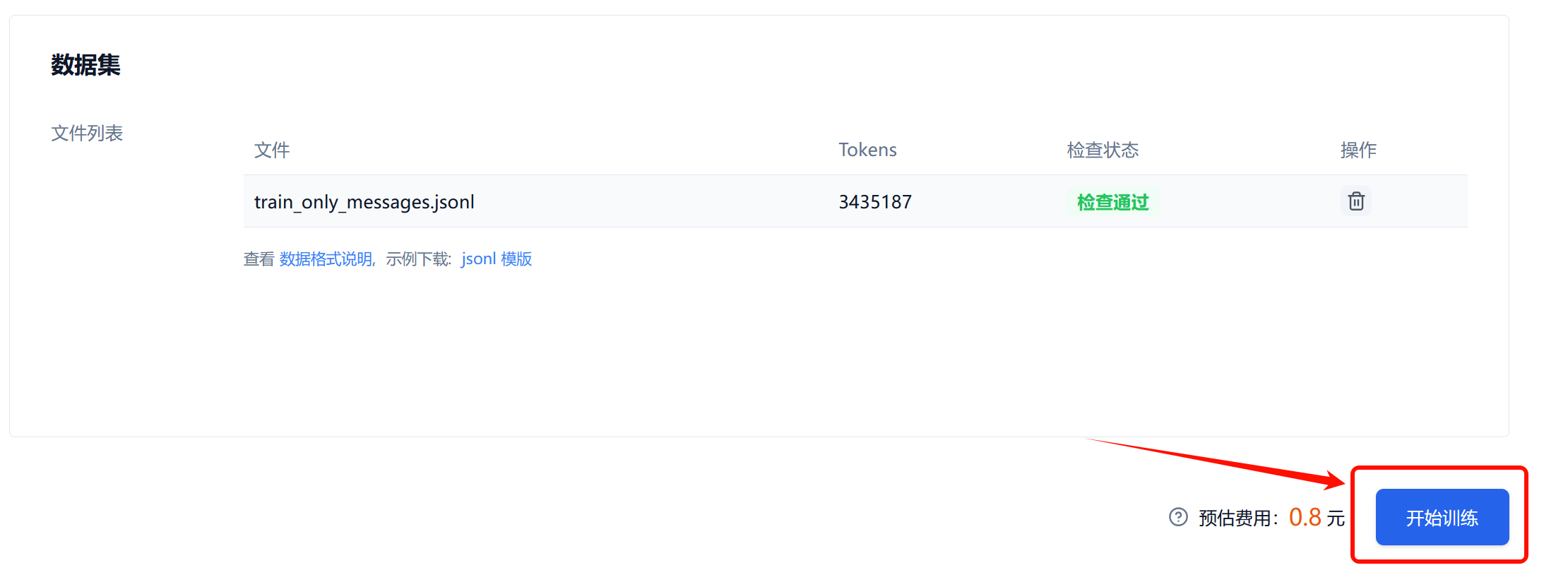
最后是上传文件了,若数据集检测成功,则开始训练按钮点亮,点击即可开始训练模型,如下图所示:

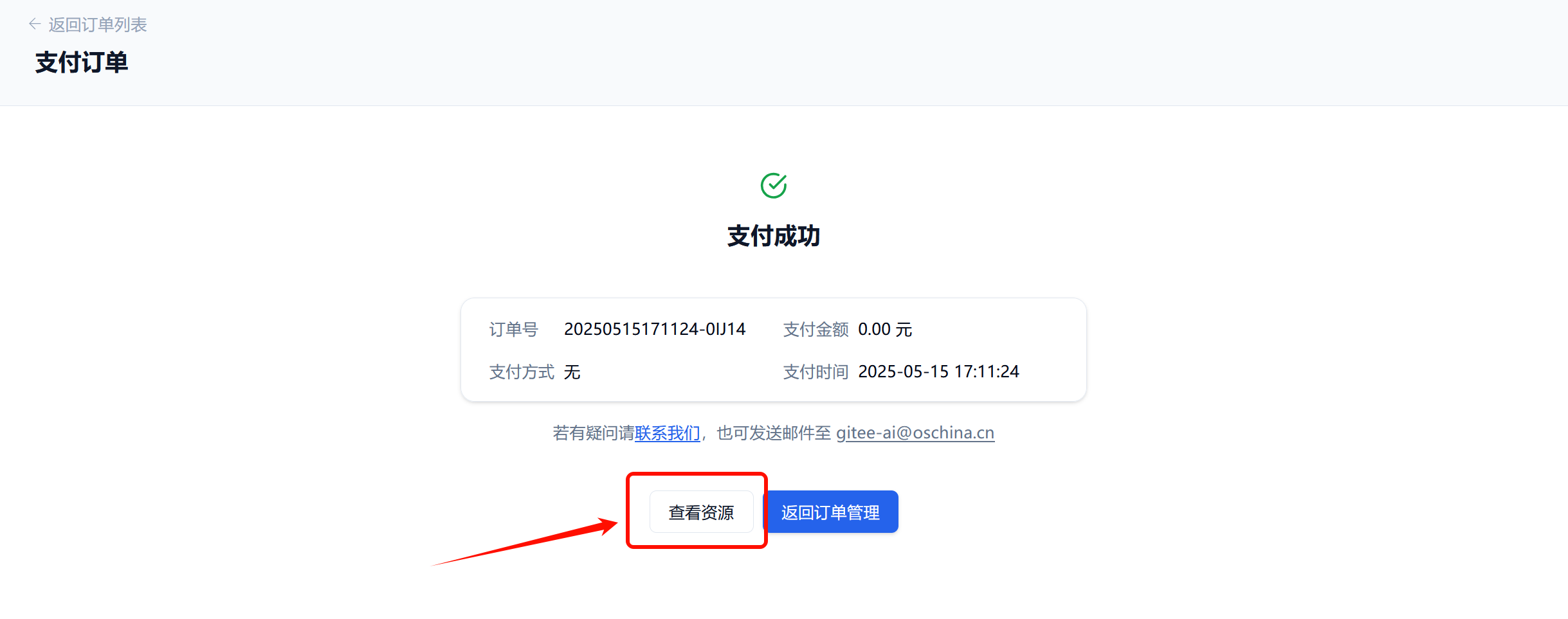
点击“开始训练”后需要提交订单并付款,成功后点击查看资源,如下图所示:
之后就可以在训练页面看到自己的训练进度和结果了~
训练与保存
刚进入到训练页面时,须排队请求GPU资源,训练初始化成功后如下图所示,表示已经开始训练了。
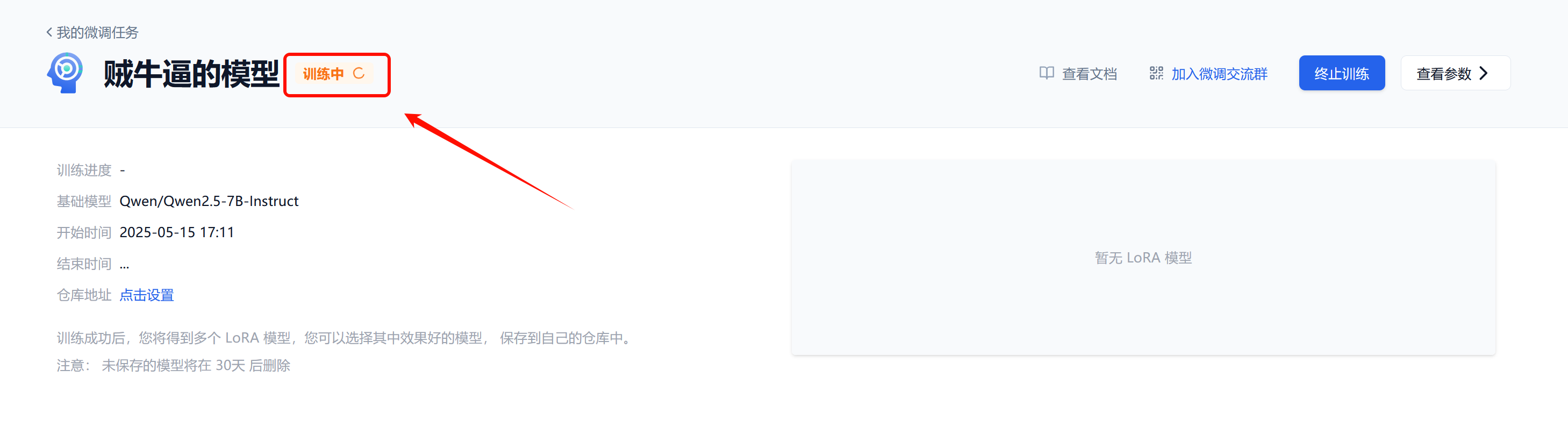
您可以在此处看到训练进度、时间等 LoRA 信息,一个完整的训练结束的 LoRA 如下图所示:
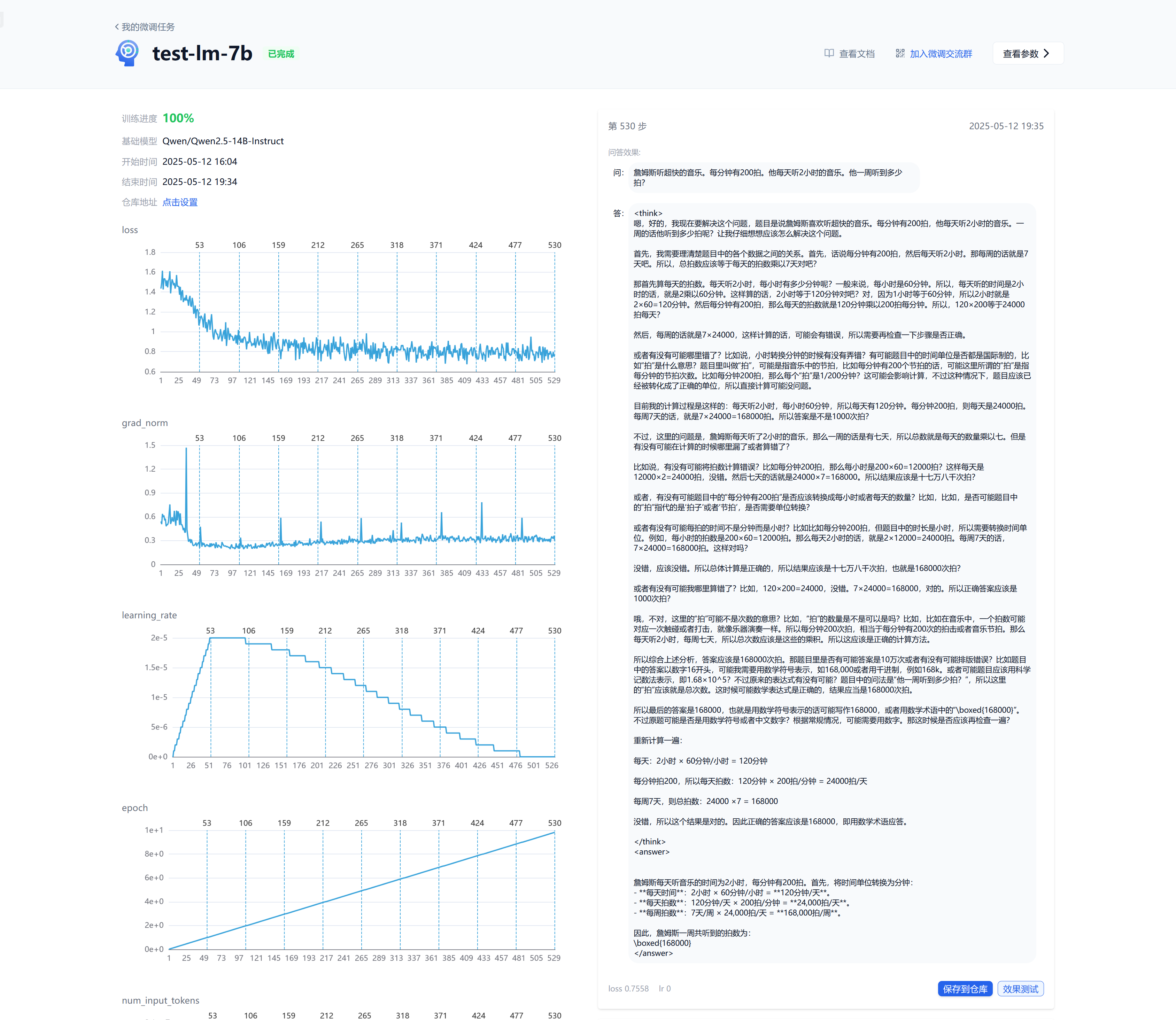
左侧列是一些重要的训练过程指标展示,它可以从指标上反映训练的好坏,以及时终止较差的训练。右侧列是每个训练完成的 LoRA 检查点,我们提前从您的数据中拿取一个用于自动的生成结果,这可以看到随着训练生成内容的变化是否符合您训练数据的偏好。
如果您觉得某一步的 LoRA 符合初步需求,可以点击“效果测试”,会打开下图的弹窗:
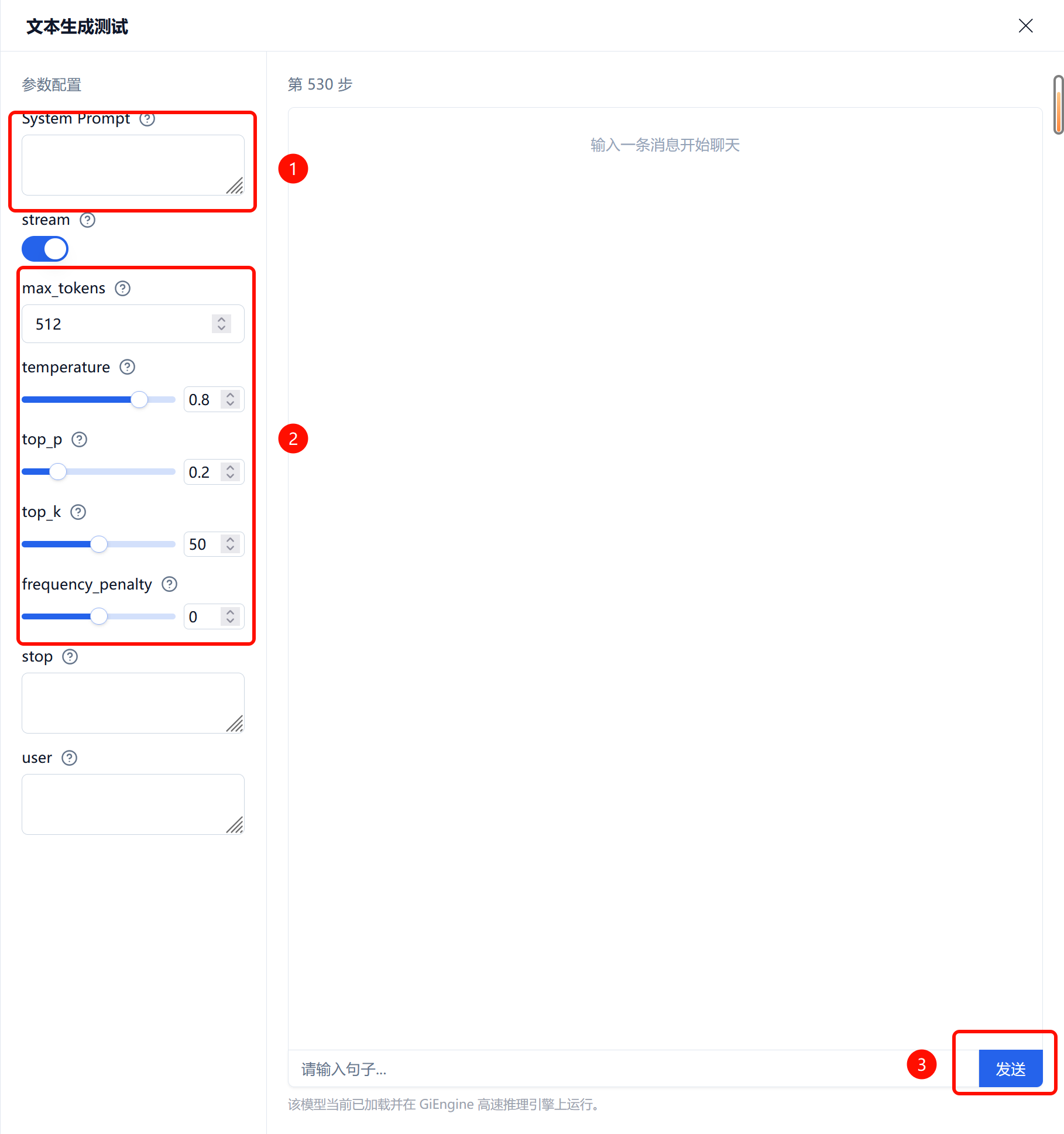
如果您的数据集中有系统提示词,则需要在此处填写。这些默认参数在正常情况下有着比较好和稳定的输出内容,在确认输入内容无误后点击发送,即可查看回复结果。
如果两种测试结果都符合您的需求,就可以将该训练检查点的 LoRA 保存到您自己的仓库中了。首先点击设置仓库,如下图所示:

设置完成后可转到刚才心仪 LoRA 所在的检查点,点击“保存到仓库”,如下图所示:
当显示保存成功时,这个 LoRA 文件就到您的仓库了,您可以选择继续在平台体验效果,也可以将 LoRA 进行后续的任何操作。
以上就是所有的操作了,祝您可以顺利微调出自己心仪的 LoRA 模型~