声纹(声音克隆)
基本介绍
声纹技术是指通过人工智能模型,生成与特定声音特征一致的语音音频。将声纹信息与文本内容结合,可以生成具有特定音色、语调和�语速的语音。声纹技术广泛应用于个性化语音合成、语音助手、智能客服等领域。
目前模型广场已上线的语音合成模型基本都支持声纹,但是每个模型使用声纹的方式有所不同,主要包含如下几种方式:
- 内置声纹
- 直接使用录音作为声纹
- 使用录音与对应的文本内容作为声纹
- 使用
.pt格式的声纹文件
一. 内置声纹
部分模型不支持自定义声纹,它内置了为数不多的几个声纹信息,用户可以直接使用这些模型进行语音合成。例如 Spark-TTS-0.5B 可以选择内置的男生、女生声纹。

二. 直接使用录音作为声纹
IndexTTS-1.5 使用录音作为声纹信息,用户只需上传一段音频文件,模型会自动提取音频中的声音特征进行语音合成。

三. 使用录音与对应的文本内容作为声纹
如下图所示,F5-TTS 、 CosyVoice2-0.5B 和 Step-Audio-TTS-3B 模型的声纹要求都是录制一段 WAV 格式的示例录音,以及对该录音的文字内容作为声纹信息。请使用录音软件录制吐字清晰的音频,时长建议保持在 5-15 秒,文件格式为 .wav ,建议文件不易过大。

四. 使用 .pt 格式的声纹文件
只需在语音生成模型的参数设置中配置 voice_url ,以 URL 的形式传递 .pt 格式的声纹文件给模型,即可生成和文件中声音特征一致的音频。主要包括以下几个关键步骤:
- 制作.pt 格式的声�纹文件,可以通过音频文件转制而成,不同模型所要求的声纹文件不同:
CosyVoice-300M和fish-speech-1.2-sft模型可使用平台提供的声纹文件接口制作。ChatTTS模型可使用ChatTTS声音克隆工具 http://region-9.autodl.pro:41137/ 制作(目前该页面已不可访问,官方不再提供直接生成 pt 文件的服务)。
-
将制作好的
.pt格式的声纹文件,存放在公开可下载的地址,比如放在您的Gitee代码仓库中。 -
复制下载地址至下图模型中的
voice_url参数,最后输入文本并运行,就能生成与文件音色一致的声音了。

步骤1:制作.pt 格式的声纹文件
1.1 制作音频文件
使用录音软件录制吐字清晰的音频,时长建议保持在 5-15 秒,文件格式为 .mp3 或 .m4a ,建议文件不易过大。
1.2 生成 CosyVoice-300M 和 fish-speech-1.2-sft 模型的声纹文件
将音频文件上传至平台提供的声音特征提取接口,下面是接口的详细说明:
功能描述
该接口用于处理音频文件,提取关键音频特征
注意事项
- 文件大小限制:小于 5 M
- 支持的音频格式:.mp3 或 .m4a
- 该接口可以提取音频中的关键特征用于后续处理和分析
调用方式
HTTPS 调用
POST https://ai.gitee.com/v1/audio/voice-feature-extraction
请求参数
| 参数位置 | 名称 | 类型 | 必填 | 说明 |
|---|---|---|---|---|
| Header | Authorization | string | 是 | 访问令牌,可在工作台->设置->访问令牌,进行生成获取。值格式:"Bearer access_token",示例值:"Bearer t-g1044qeGEDXTB6NDJOGV4JQCYDGHRBARFTGT1234" |
| form-data | file | file | 是 | 语音内容。注意:Content-Type 为 application/octet-stream,示例值为二进制文件。 |
| form-data | prompt_text | string | 是 | 提词内容。注意:与录音内容一致的文字描述。 |
| form-data | model | string | 是 | 模型名称:CosyVoice-300M |
返回参数
HTTP 状态码为 200 时,表示成功。返回文件二进制流。
cURL 示例
cURL
--location --request POST 'https://ai.gitee.com/vi/audio/voice-feature-extraction'
--header 'Authorization: Bearer 输入您的访问令牌 '
--form 'model="CosyVoice-300M"'
--form 'file=@"上传.mp3 或.m4a格式的文件"'
--form 'prompt_text="和录音内容一致的文字描述“’
使用 APIfox 接口工具请求示例
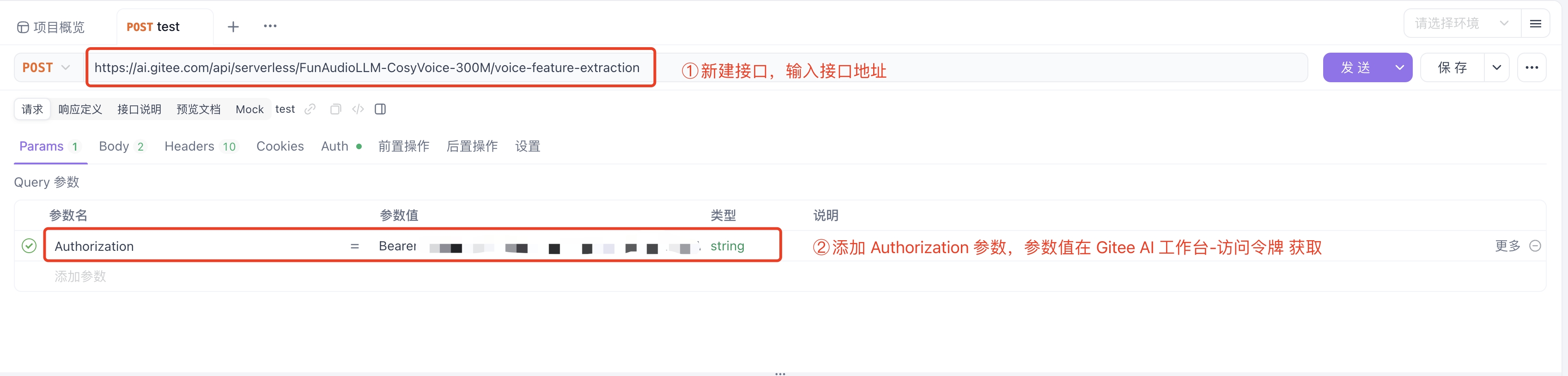
1)新建接口井输入接口地址。
2)添加 Authorization 参数,参数值可以在模力方舟工作台-访问令牌获取。
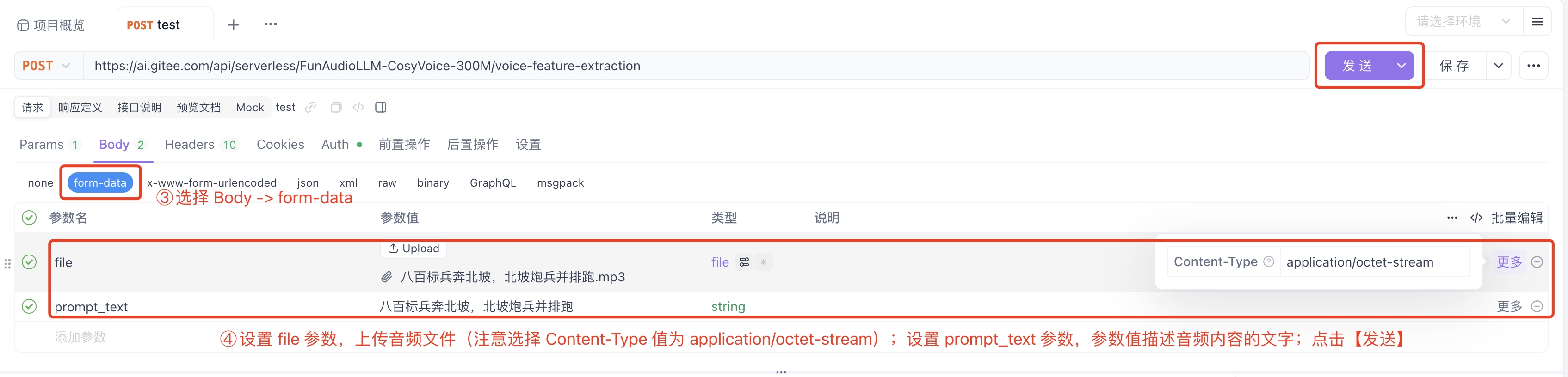
3)选择 Body -> form-data 。
4)添加 file 参数,并上传音频文件;添加 prompt_text 参��数,参数值是和录音内容一致的文字描述,添加完成后点击发送。
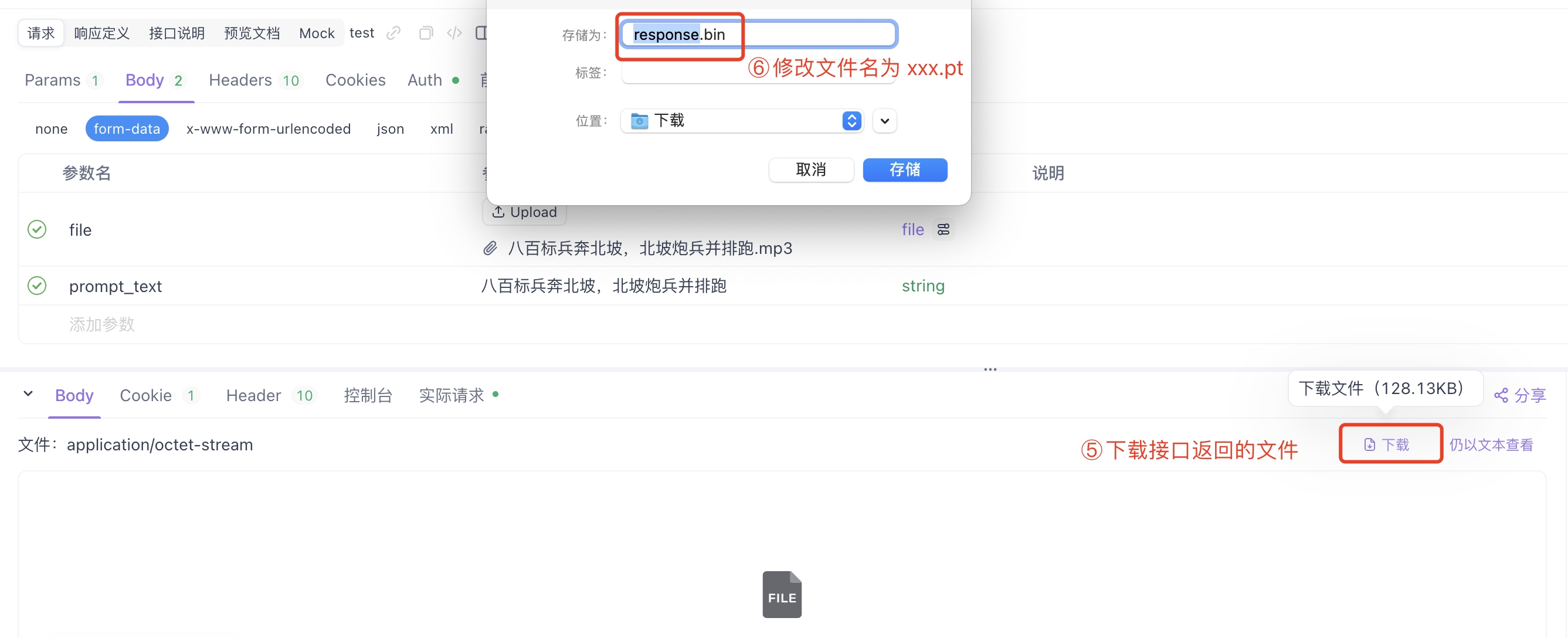
5)请求成功后,下载接口返回的文件,并修改文件名为 xxxx.pt。
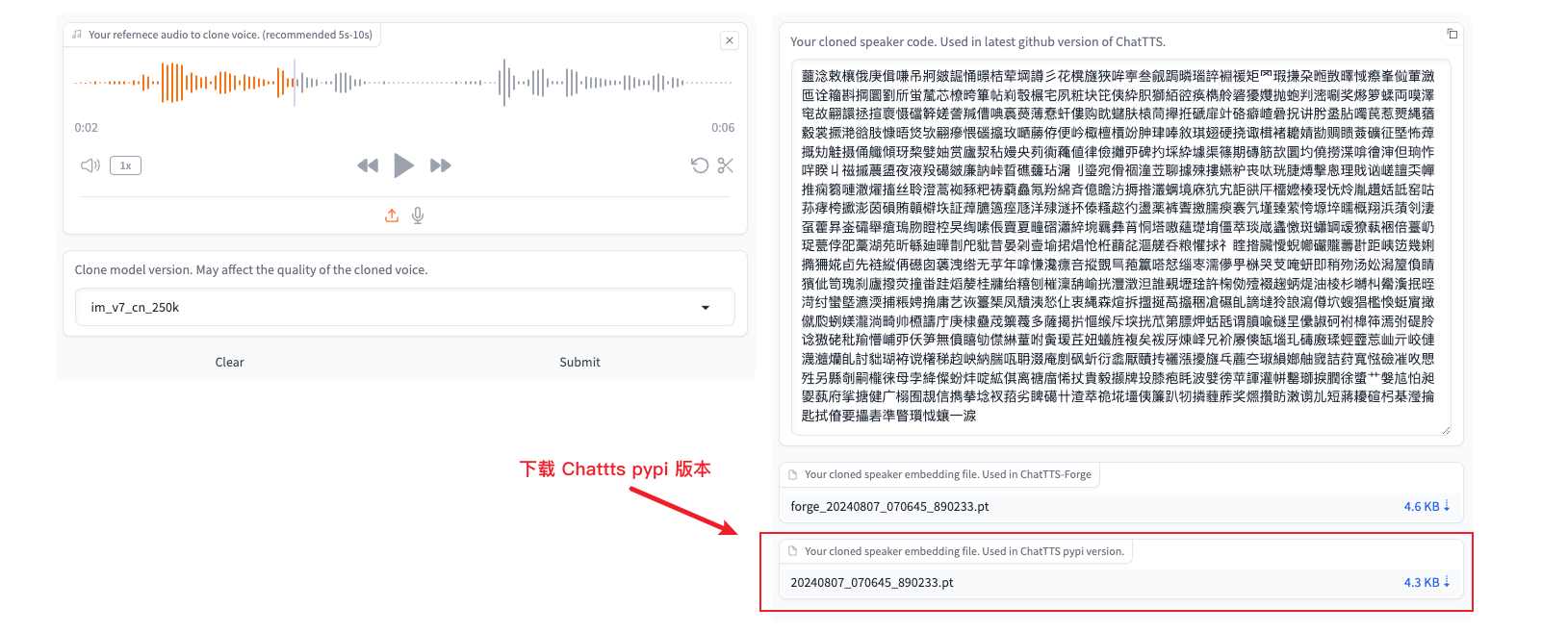
1.3 生成 ChatTTS 模型的声纹文件
1) 访问 Chattts 的声音克隆工具 http://region-9.autodl.pro:41137/
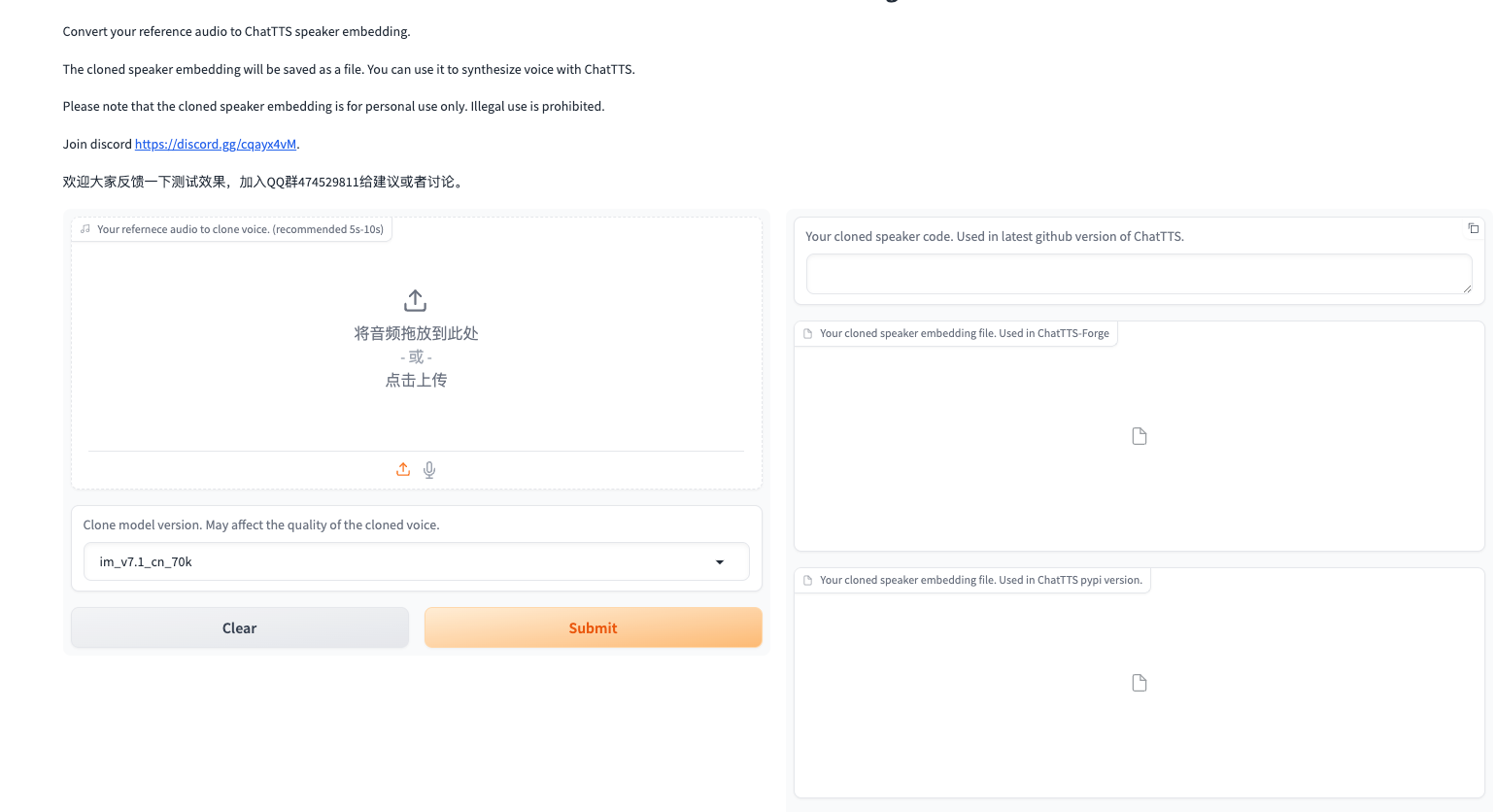
2)上传/录制音频,点击 submit 。等待生成
3) 生成成功后,请下载 ChatTTS pypi 版本的 pt 文件
步骤2:上传声纹文件并获取下�载地址
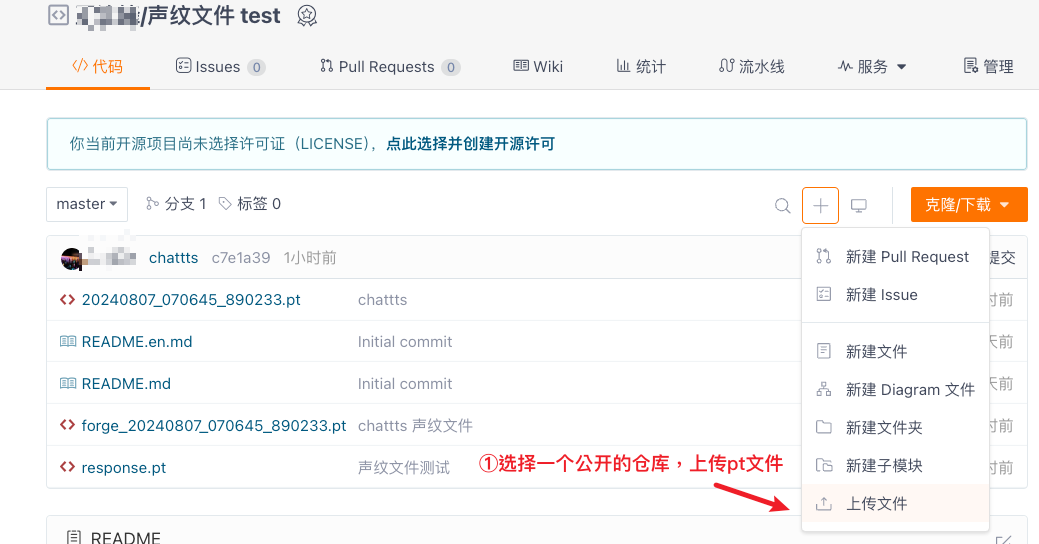
语音生成模型的 voice_url 参数需要读取声纹文件,所以我们需要将声纹文件上传至网盘或其他可下载的公共空间,并获取文件下载的 URL,配置到语音模型的 voice_url 参数即可。
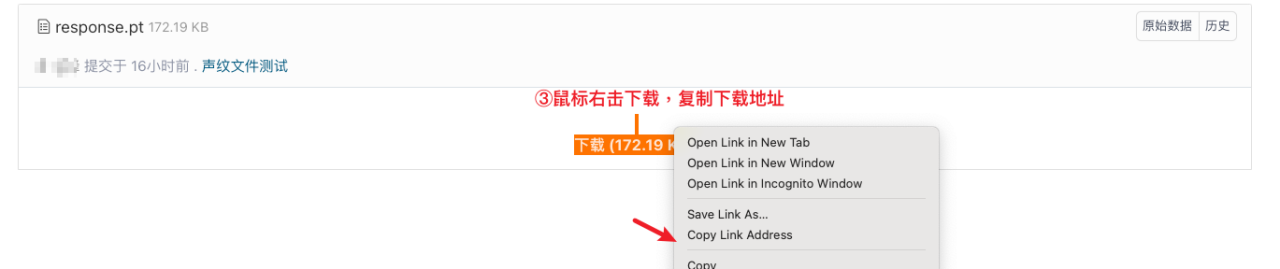
推荐您在 Gitee 创建或选择一个公开的仓库,将 .pt 文件上传至仓库中。在 Gitee 仓库中找到上传的文件,点击文件名称进入下载,鼠标右击下载并复制下载地址,如下所示:

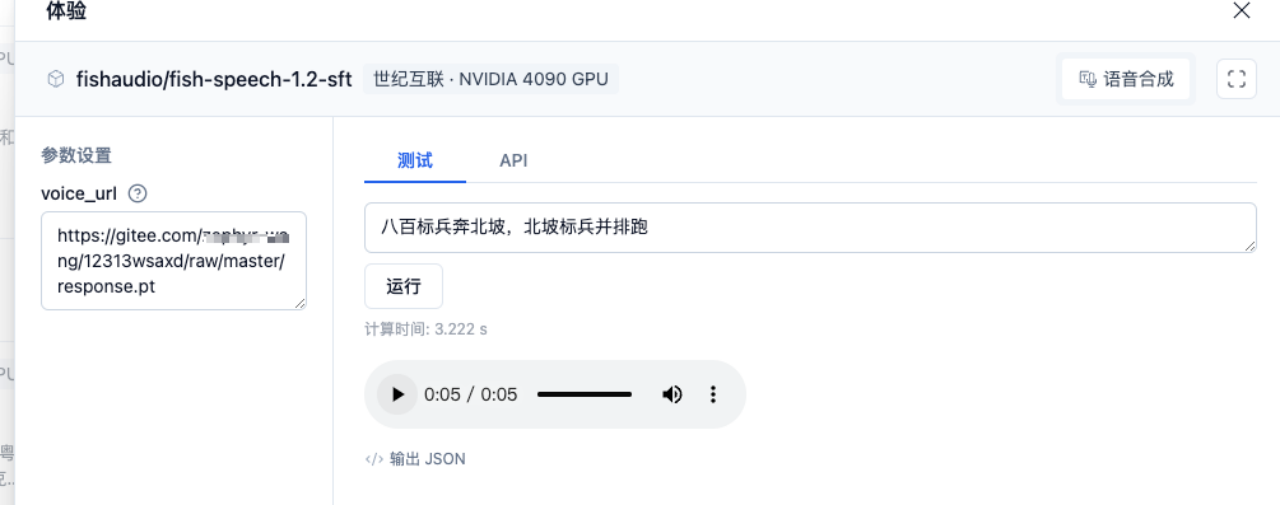
步骤3:在模型参数中粘贴地址
根据您生成的 pt 文件类型,选择 CosyVoice-300M、ChatTTS、fish-speech-1.2-sft ,粘贴声纹文件下载地址到 voice_url 参数,输入文字并运行。即可生成和声纹音色一致的声音。
您可以制作个人或特定声音的声纹文件 URL,体验不同模型生成效果,将模型 API 集成到您的业务中,实现多种有趣又有用的应用。