语音模型应用场景
语音模型包括自动语�音识别(ASR)和语音合成(TTS)两大类型,为音频内容的理解和生成提供强大能力。
自动语音识别模型
自动语音识别模型能够将语音转换为文字,支持多种语言和方言,广泛应用于各种需要语音理解的场景。

主要应用场景
会议实时转录
在远程协作情景中,实时转写跨语言线上会议内容,生成带时间戳的对话记录,支持关键词检索与重点标记。
典型用例:
- 远程会议自动记录
- 多语言会议同步翻译
- 会议纪要自动生成
视频内容配字幕
在媒体生产情景中,为短视频/长片纪录片自动生成多语言字幕,同步输出字幕文件(SRT/VTT)。
典型用例:
- 视频自动字幕生成
- 多语言字幕制作
- 媒体内容本地化
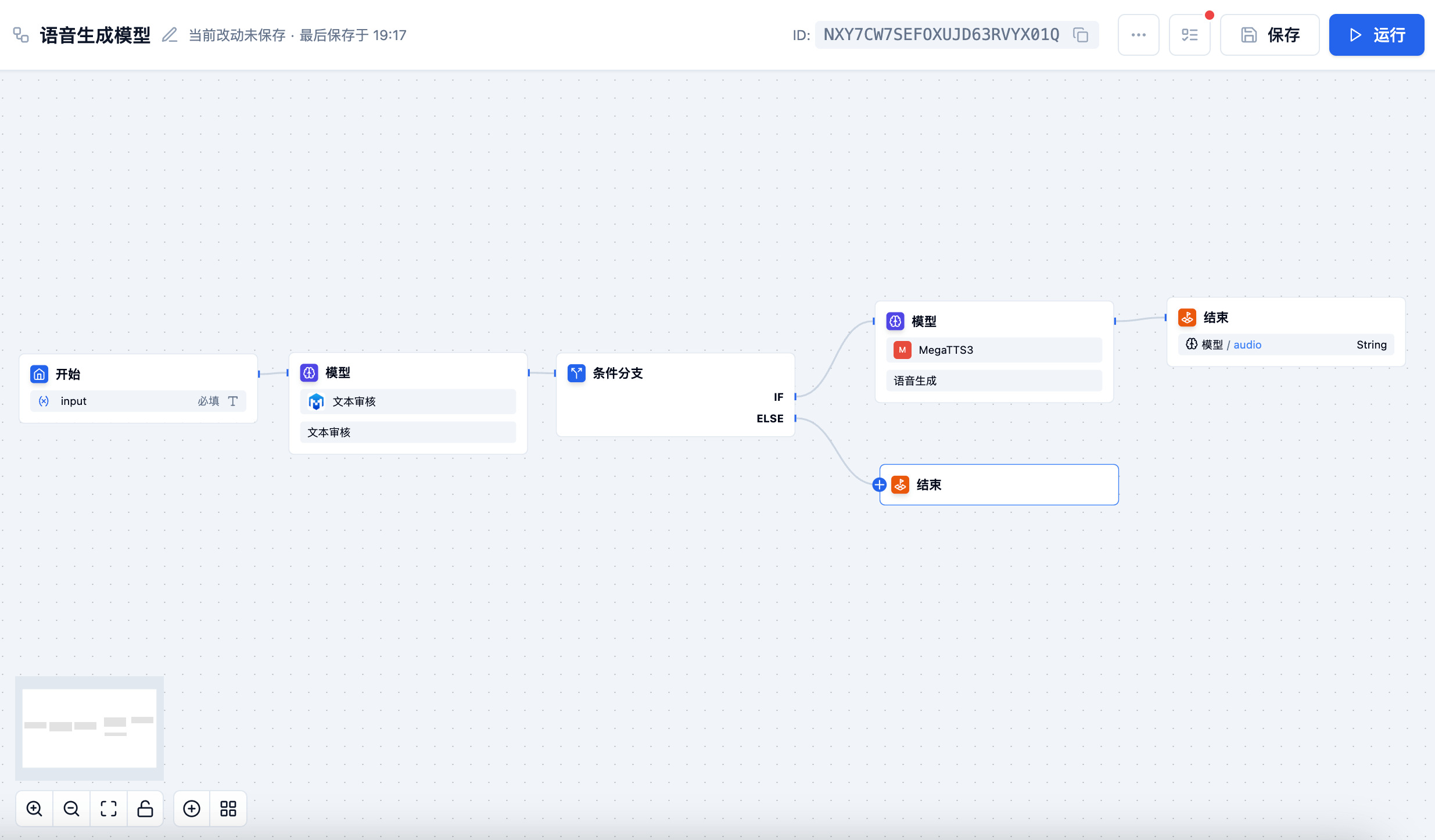
语音合成模型
语音合成模型能够将文字转换为自然流畅的语音,支持多种音色和情感表达。
主要应用场景
多角色有声内容创作
生成不同性别/年龄的旁白角色音,批量输出带情感变化的配音片段。
典型用例:
- 有声小说制作
- 广告配音生成
- 播客节目制作
- 角色扮演音频
长文本语音播报
将小说章节转换为��自然流畅的朗读音频,自动插入呼吸停顿/强调重音。
典型用例:
- 长篇小说朗读
- 新闻播报生成
- 学习材料朗读