文本生成模型应用场景
文本生成模�型(LLM) 节点是能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在 API 流水线的不同环节使用。包含多种主流模型,如DeepSeek、Qwen系列等。
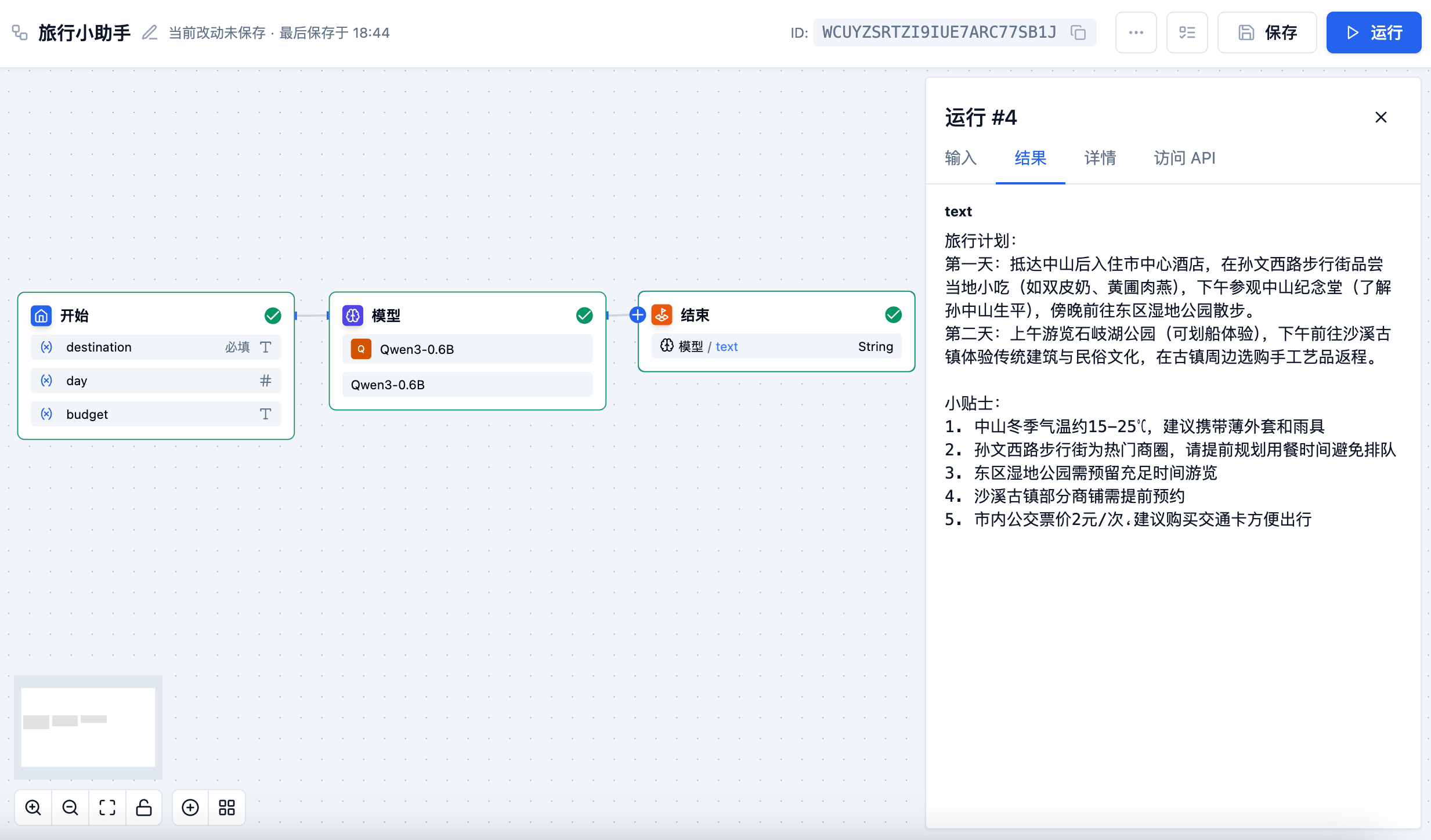
主要应用场景
意图识别
在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
典型用例:
- 客服机器人自动分类用户问题(技术支持、退款申请、产品咨询)
- 智能路由用户请求到相应的专业客服团队
- 实时分析用户情绪,调整对话策略
文本生成
在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
典型用例:
- 营销文案自动生成
- 产品说明书批量创建
- 个性化邮件内容生成
- 社交媒体内容创作
内容分类
在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
典型用例:
- 自动邮件分拣系统
- 内容审核分类
- 文档自动归档
- 用户反馈分类分析
文本转换
在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
典型用例:
- 多语言内容本地化
- 实时聊天翻译
- 文档翻译批处理
- 跨语言信息检索
代码生成
在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
典型用例:
- 自动化测试用例生成
- API文档生成
- 代码重构建议
- 编程教学辅助
配置要点
- 模型选择:根据任务复杂度选择合适的模型规模
- 提示词优化:针对具体场景设计专业的提示词模板
- 参数调整:根据输出要求调��整temperature、max_tokens等参数
- 变量设置:合理设置输入输出变量,便于上下游节点数据传递